Home > Learning Center > Round Trip Time (RTT)

Article's content
Round trip time (rtt), what is round trip time.
Round-trip time (RTT) is the duration, measured in milliseconds, from when a browser sends a request to when it receives a response from a server. It’s a key performance metric for web applications and one of the main factors, along with Time to First Byte (TTFB), when measuring page load time and network latency .
Using a Ping to Measure Round Trip Time
RTT is typically measured using a ping — a command-line tool that bounces a request off a server and calculates the time taken to reach a user device. Actual RTT may be higher than that measured by the ping due to server throttling and network congestion.

Example of a ping to google.com
Factors Influencing RTT
Actual round trip time can be influenced by:
- Distance – The length a signal has to travel correlates with the time taken for a request to reach a server and a response to reach a browser.
- Transmission medium – The medium used to route a signal (e.g., copper wire, fiber optic cables) can impact how quickly a request is received by a server and routed back to a user.
- Number of network hops – Intermediate routers or servers take time to process a signal, increasing RTT. The more hops a signal has to travel through, the higher the RTT.
- Traffic levels – RTT typically increases when a network is congested with high levels of traffic. Conversely, low traffic times can result in decreased RTT.
- Server response time – The time taken for a target server to respond to a request depends on its processing capacity, the number of requests being handled and the nature of the request (i.e., how much server-side work is required). A longer server response time increases RTT.
See how Imperva CDN can help you with website performance.
Reducing RTT Using a CDN
A CDN is a network of strategically placed servers, each holding a copy of a website’s content. It’s able to address the factors influencing RTT in the following ways:
- Points of Presence (PoPs) – A CDN maintains a network of geographically dispersed PoPs—data centers, each containing cached copies of site content, which are responsible for communicating with site visitors in their vicinity. They reduce the distance a signal has to travel and the number of network hops needed to reach a server.
- Web caching – A CDN caches HTML, media, and even dynamically generated content on a PoP in a user’s geographical vicinity. In many cases, a user’s request can be addressed by a local PoP and does not need to travel to an origin server, thereby reducing RTT.
- Load distribution – During high traffic times, CDNs route requests through backup servers with lower network congestion, speeding up server response time and reducing RTT.
- Scalability – A CDN service operates in the cloud, enabling high scalability and the ability to process a near limitless number of user requests. This eliminates the possibility of server side bottlenecks.

Using tier 1 access to reduce network hops
One of the original issues CDNs were designed to solve was how to reduce round trip time. By addressing the points outlined above, they have been largely successful, and it’s now reasonable to expect a decrease in your RTT of 50% or more after onboarding a CDN service.
Latest Blogs

- Imperva Threat Research

Gabi Sharadin
, Muly Levy
Jul 23, 2024 2 min read

Erez Hasson
, Lynn Marks
Jul 1, 2024 3 min read

Jun 20, 2024 4 min read

May 17, 2024 5 min read

Grainne McKeever
May 8, 2024 3 min read

Apr 16, 2024 4 min read

Mar 13, 2024 2 min read

Mar 4, 2024 3 min read
Latest Articles
- Network Management
176.5k Views
157.5k Views
113.4k Views
104.6k Views
103.2k Views
61.6k Views
56.4k Views
The DDoS Threat Landscape 2024
111% increase in DDoS attacks mitigated by Imperva
2024 Bad Bot Report
Bad bots now represent almost one-third of all internet traffic
The State of API Security in 2024
Learn about the current API threat landscape and the key security insights for 2024
Protect Against Business Logic Abuse
Identify key capabilities to prevent attacks targeting your business logic
The State of Security Within eCommerce in 2022
Learn how automated threats and API attacks on retailers are increasing
Prevoty is now part of the Imperva Runtime Protection
Protection against zero-day attacks
No tuning, highly-accurate out-of-the-box
Effective against OWASP top 10 vulnerabilities
An Imperva security specialist will contact you shortly.
Top 3 US Retailer
What is Round Trip Time - RTT vs TTFB vs Latency

Round Trip Time (RTT) is a metric that measures the time taken by a network packet to travel from sender to receiver and then back from receiver to sender.
RTT = Latency (Client to Server) + Server Processing Time + Latency (Server to Client)
RTT is a great metric to evaluate network performance but not the best at measuring how well the website is served to the end users. TTFB is a better metric for understanding server performance. Nevertheless, RTT directly influences TTFB and hence we must ensure that our website has a low RTT.
Here's a quick illustration of Round Trip Time.

In the above illustration, you can see that the time period between the Request sent from the client to the Response received by the client is the Round Trip Time. Apart from the latency, it might also include a little server processing delay.
When measuring RTT, we ideally send a request such as ping that involves minimal processing and resources. This ensures that we can minimize the server processing and our RTT value mainly comprises of latency at both ends.
How to Measure Round Trip Time
To measure Round Trip Time, you can either open Terminal on Mac or Linux or open Command Prompt/Powershell on Windows. Use the ping command for any domain name or IP.
Here's an example showing the ping command for google.com.

You can use -c to limit the number of requests you want to send. Once the process is done, you'll get a summary of the RTT. It will list the minimum, average, maximum, and standard deviation values for the RTT. The farther you are from the physical server (or CDN's point of presence), the higher will be the RTT value.
What Factors Affect Round Trip Time
1) physical distance .
The longer the physical distance between the client and the server, the higher will be RTT. This applies to latency and TTFB as well.
2) Network Traffic
If any part of the network is congested due to high usage, there will be delays as the packets have to wait in a queue.
3) Network Hops Count
The more routers or servers a packet has to travel through, the higher will be the RTT. This is because each device will take some time to process it.
4) Server Response Time
Since Round Trip Time consists of the time when a request is sent by the client and the time when it is received back by the client, it adds some delay as the server needs to process the request in order to respond back. While measuring RTT, we try to minimize this time by using a simple request such as ping. However, for more complex requests, the server processing time is high and adds to the RTT value.
5) Transmission Medium
Optical Fiber offers the lowest RTT followed by other Wired connections such as Copper Cables. Wireless networks such as Wi-Fi, 5G, 4G, and Satellite Internet such as Starlink will have higher RTT.
6) Routing Paths
If the packet takes a more complex path over the internet, it could lead to a higher RTT. Some CDN Providers offer services that optimize the network paths.
7) Packet Size
The lower the size of the packet, the faster it can be transmitted.
RTT vs TTFB vs Latency
It is easy to get confused between these three as they all are very similar. To understand their difference better, let's start with the easiest one, i.e., latency.
Latency is only a one-way delay. It is the time taken by a network packet to travel from sender to receiver (or from receiver to sender).
RTT (Round Trip Time) is the two-way delay. It is the time taken by a network packet to travel from sender to receiver and then back to sender from the receiver.
TTFB (Time to First Byte) is a metric that is quite similar to Round Trip Time but it is measured for an HTTP request and includes the server processing delay along with the round trip time. SpeedVitals also offers a TTFB Test that you could check out.
RTT & Web Performance
Round Trip Time is an important metric for Web Performance as it directly influences TTFB which in turn affects various Web Vitals including Largest Contentful Paint (LCP) and Interaction to Next Paint (INP). Let us discuss how RTT affects Core Web Vitals and how to measure RTT for real users.
Impact on Core Web Vitals
Time to First Byte (TTFB) metric consists of Round Trip Time as well as Server Processing Time. It plays an important in the calculation of First Contentful Paint (FCP) and Largest Contentful Paint (LCP). Even if your website has a fast backend/server and your Frontend is well-optimized, you can still have a poor LCP score if the Round Trip Time is high.
Since a high RTT value increases TTFB, this results in a delay until all the critical resources are loaded and the website becomes interactive. This can also result in slower event handling and higher input latency. All of these factors can increase INP (Interaction to Next Paint), which is a new Core Web Vitals metric.
The only metric RTT doesn't have a direct impact on is Cumulative Layout Shift (CLS). Nevertheless, RTT has a direct impact on 2/3rd of Core Web Vitals.
We also have a free tool to check out your Core Web Vitals score. You can check it out on Core Web Vitals Checker .
Check RTT using CrUX API
The Chrome User Experience Report (CrUX) has recently started including the RTT values. You can learn more about the same on the metrics page of CrUX API Documentation .
However, this RTT value is measured for an HTTP request and not for a simpler request like ping. This would be ideal in the context of Web Performance but it could differ from measuring RTT via ping, and also because it is being measured for real users.
How to Reduce Round Trip Time
Our article on reducing TTFB covers both aspects (Reducing Server Response Time and latency). Some of the suggestions in that article will be applicable to reducing RTT as well.
Here are some suggestions that can help reduce the RTT of your website.
1) Use a CDN
As discussed earlier, using a CDN can dramatically reduce both RTT and TTFB as it makes copies of your website resources in multiple locations. When a user requests your website, the CDN serves the user through its closest Point of Presence.
You can refer to our article to find out the best CDN .
2) Consider using a Load Balancer
A load balancer can distribute the traffic to your origin server to multiple nodes and helps prevent network congestion during traffic spikes. Moreover, having multiple servers across the globe can reduce network delay as the content gets served from the node closest to the user (in case of no CDN, dynamic content, or Cache Miss).
3) Optimize Network Paths
Some CDNs offer features or add-on services that can optimize network paths by smart routine. Some of the popular services include:
- Cloudflare's Argo Smart Routing
- Fastly's Dynamic Site Acceleration
- Akamai's Adaptive Media Delivery
- How to Measure Round Trip Time
- 1) Physical Distance
- 2) Network Traffic
- 3) Network Hops Count
- 4) Server Response Time
- 5) Transmission Medium
- 6) Routing Paths
- 7) Packet Size
- RTT vs TTFB vs Latency
- Impact on Core Web Vitals
- Check RTT using CrUX API
- 1) Use a CDN
- 2) Consider using a Load Balancer
- 3) Optimize Network Paths
- Skip to primary navigation
- Skip to main content
- Skip to footer
Cyara Customer Experience Assurance Platform
Blog / CX Assurance
December 12, 2023
What is Round-trip Time and How Does it Relate to Network Latency?

Tsahi Levent-Levi, Senior Director, Product
Round-trip time (RTT) is an important metric that can indicate the quality of communications available between two end-points. It’s a metric that our team often discusses with customers because it directly relates to the service quality experienced. RTT can be impacted by a range of design decisions, especially concerning network topology. However, there is some confusion around what exactly RTT is, how it relates to latency, how it can impact your service, and how you can improve it.
What is Round-trip Time?
One of our most viewed dashboard metrics in our Cyara testRTC product suite is RTT. This is the time it takes for a packet to go from the sending endpoint to the receiving endpoint and back. There are many factors that affect RTT, including propagation delay, processing delay, queuing delay, and encoding delay. These factors are generally constant for a given pair of communicating endpoints. Additionally, network congestion can add a dynamic component to RTT.
Propagation delay is the network distance between the two endpoints. It is the route taken by the data across the various networks, through different network switches and routers to get from the sending endpoint to the receiving endpoint. Sometimes, this may be aligned with geographical distances and sometimes it may not. Propagation delay is usually the dominant component in RTT. It ranges from a few milliseconds to hundreds of milliseconds, depending on whether the endpoints are separated by just a few kilometers or by an entire ocean.
The remaining components (processing, queuing, and encoding delays) can vary by the number of nodes in the network connecting endpoints. When only a few router hops separate the endpoints, these factors are insignificant. However, the more hops, the higher the delay, since each network node needs to receive, process and route all the data towards the next hop, adding its own milliseconds of delay to the total RTT calculation.
Impact of Network Topology
In real-time communications, we must consider the impact of network topology on RTT. Any infrastructure-based topology introduces incremental delays when compared with a peer-to-peer connection. When media is anchored by a multipoint control unit MCU , SFU , or TURN server, additional processing, queuing and encoding delays occur. But, more importantly, an infrastructure topology can add significant propagation delay depending on where the server is located relative to the endpoints.

Figure 1: Infrastructure Topology
Hairpinning occurs when media is anchored in a location that is geographically remote from an endpoint, this adds significant propagation delay, when compared to a peer connection. This is why the placement of infrastructure can be critical to delivering low RTT and a high-quality user experience. The further the media server is from the sending and receiving endpoints, the higher the RTT value and the lower the service quality.

Figure 2: The media server is located further away than necessary from the sending and receiving endpoints, resulting in a high round-trip time.

Figure 3: The media server is located between the sending and receiving endpoints, resulting in a lower round-trip time.
Clearing Up a Few Misconceptions
RTT and ping time are often considered synonymous. But while ping time may provide a good estimate of RTT, it is different. This is because most ping tests are executed within the transport protocol using internet control messaging protocol (ICMP) packets. In contrast, RTT is measured at the application layer and includes the additional processing delay produced by higher level protocols and applications (e.g. HTTPS). In WebRTC, RTT on the media streams is calculated by looking at the secure real-time transport protocol (SRTP) packets themselves. This provides the closest measure to what the actual media in a session feels like in terms of RTT.
Network latency is closely related, but different from RTT. Latency is the time it takes for a packet to go from the sending endpoint to the receiving endpoint. Many factors affect the latency of a service, including:
- Network congestion
- Packet loss and jitter
- Traffic prioritization
- Server load
- Codecs and encryption
Therefore, latency is not explicitly equal to half of RTT, because delays may be asymmetrical between any two given endpoints. For example, RTT includes processing delay at the echoing endpoint.
How Does RTT Affect Your Real-time Communications Service?
As a rule of thumb, the lower the RTT, the higher the media quality for that session is. Our focus is on ensuring the delivery of live, highly interactive services and conversations. Doing that requires a low delay from the time a user speaks until the intended recipients hear the spoken words.
At Cyara, we’ve made RTT a central focus in all of our WebRTC services. We ensure it is available to you in both aggregate form (in highlight dashboards) as well as in drill down analysis charts where you can analyze RTT over time.
Read more about: Cyara testRTC , Latency , Round-Trip Time (RTT) , Web Real-Time Communication (WebRTC) , WebRTC Monitoring
Subscribe for Updates
Join our email list, and be among the first to learn about new product features, upcoming events, and innovations in AI-led CX transformation.
Written by Vasilena Markova • August 21, 2024 • 12:56 pm • Internet
Round-Trip Time (RTT): What It Is and Why It Matters
Round-Trip Time (RTT) is a fundamental metric in the context of network performance, measuring the time it takes for data packets to complete a round trip from source to destination and back. Often expressed in milliseconds (ms), RTT serves as a critical indicator for evaluating the efficiency and reliability of network connections. In today’s article, we dive into the concept of RTT, exploring how it works, why it matters in our digital lives, the factors that influence it, and strategies to enhance it. Whether you’re a casual internet user seeking a smoother online experience or a network administrator aiming to optimize your digital infrastructure, understanding this metric is critical in today’s interconnected world.
Table of Contents
What is Round-Trip Time (RTT)?
Round-Trip Time is a network performance metric representing the time it takes for a data packet to travel from the source to the destination and back to the source. It is often measured in milliseconds (ms) and is a crucial parameter for determining the quality and efficiency of network connections.
To understand the concept of RTT, imagine sending a letter to a friend through the postal service. The time it takes for the letter to reach your friend and for your friend to send a reply back to you forms the Round-Trip Time for your communication. Similarly, in computer networks, data packets are like those letters, and RTT represents the time it takes for them to complete a round trip.
How Does it Work?
The concept of RTT can be best understood by considering the journey of data packets across a network. When you request information from a web server, for example, your device sends out a data packet holding your request. This packet travels through various network devices in between, such as routers and switches, before reaching the destination server. Once the server processes your request and prepares a response, it sends a data packet back to your device.
Round-Trip Time is determined by the time it takes for this data packet to travel from your device to the server (the outbound trip) and then back from the server to your device (the inbound trip). The total RTT is the sum of these two one-way trips.
Let’s break down the journey of a data packet into several steps so you can better understand the RTT:
- Sending the Packet: You initiate an action on your device that requires data transmission. For example, this could be sending an email, loading a webpage, or making a video call.
- Packet Travel: The data packet travels from your device to a server, typically passing through multiple network nodes and routers along the way. These middle points play a significant role in determining the RTT.
- Processing Time: The server receives the packet, processes the request, and sends a response back to your device. This processing time at both ends also contributes to the Round-Trip Time.
- Return Journey: The response packet makes its way back to your device through the same network infrastructure, facing potential delays on the route.
- Calculation: It is calculated by adding up the time taken for the packet to travel from your device to the server (the outbound trip) and the time it takes for the response to return (the inbound trip).
Experience Industry-Leading DNS Speed with ClouDNS!
Ready for ultra-fast DNS service? Click to register and see the difference!
Why does it matter?
At first look, Round-Trip Time (RTT) might seem like technical terminology, but its importance extends to various aspects of our digital lives. It matters for many reasons, which include the following:
- User Experience
For everyday internet users, RTT influences the sensed speed and responsiveness of online activities. Low Round-Trip Time values lead to a seamless experience, while high RTT can result in frustrating delays and lag during tasks like video streaming, online gaming, or live chats.
- Network Efficiency
Network administrators and service providers closely monitor RTT to assess network performance and troubleshoot issues. By identifying bottlenecks and areas with high RTT, they can optimize their infrastructure for better efficiency.
- Real-Time Applications
Applications that rely on real-time data transmission, such as VoIP calls, video conferencing, and online gaming, are highly sensitive to RTT. Low RTT is crucial for smooth, interruption-free interactions.
In cybersecurity, Round-Trip Time plays a role in detecting network anomalies and potential threats. Unusually high RTT values can be a sign of malicious activity or network congestion.
Tools for Measuring RTT
Measuring Round-Trip Time is essential for understanding network performance. Two of the most commonly used tools are Ping and Traceroute. Here’s how to use them:
- Ping command
The Ping command is a fundamental tool available on most operating systems. It measures RTT by sending Internet Control Message Protocol (ICMP) echo requests to a specified IP address. It calculates the time it takes for a packet to travel to the target and back, providing the RTT in milliseconds. This tool is valuable for basic network diagnostics, helping you identify if a host is reachable and how long it takes to communicate with it. You can easily use it by following these steps:
- Open Command Prompt (Windows) or Terminal (macOS/Linux).
- Type “ping” and the target domain or IP address. Here is an example: ping domain.com
- Press Enter.
The output will display the RTT in milliseconds for each packet sent.
- Traceroute/Tracert
Traceroute (or Tracert in Windows) is a diagnostic tool that goes beyond just measuring RTT. It traces the entire path a packet takes to reach its destination, displaying each hop along the route and the RTT to each router. That way, it helps identify where delays or packet loss occur in the network, making it a crucial tool for finding issues in complex networks. To utilize it, follow the steps below:
- Type “tracert” (Windows) or “traceroute” (macOS/Linux) followed by the target domain or IP address. Here is an illustration: traceroute domain.com
The output will show the RTT for each hop along the route to the destination.
Factors Affecting Round-Trip Time (RTT)
Several factors can influence the metric, both positively and negatively. Therefore, understanding these factors is crucial, and it could be very beneficial for optimizing network performance:
- Distance: The physical distance between the source and destination plays a significant role. Longer distances result in higher RTT due to the time it takes for data to travel the network.
- Network Congestion: When a network experiences high volumes of traffic or congestion, data packets may be delayed as they wait for their turn to be processed. As a result, it can lead to packet delays and increased RTT.
- Routing: The path a packet takes through the network can significantly affect RTT. Efficient routing algorithms can reduce the time, while not-so-optimal routing choices can increase it.
- Packet Loss: Packet loss during transmission can occur due to various reasons, such as network errors or congestion. When lost, packets need to be retransmitted, which can seriously affect the Round-Trip Time.
- Transmission Medium: It is a critical factor influencing RTT, and its characteristics can vary widely based on the specific medium being used. Fiber optic cables generally offer low RTT due to the speed of light in the medium and low signal loss. In contrast, wireless mediums can introduce variable delays depending on environmental factors and network conditions.
How to improve it?
Improving Round-Trip Time (RTT) is a critical goal for network administrators and service providers looking to enhance user experiences and optimize their digital operations. While some factors affecting it are beyond our control, there are strategies and practices to optimize Round-Trip Time for a smoother online experience:
- Optimize Routing: Network administrators can optimize routing to reduce the number of hops data packets take to reach their destination. This can be achieved through efficient routing protocols and load balancing .
- Optimize Network Infrastructure: For businesses, investing in efficient network infrastructure, including high-performance routers and switches, can reduce internal network delays and improve RTT.
- Upgrade Hardware and Software: Keeping networking equipment and software up-to-date ensures that you benefit from the latest technologies and optimizations that can decrease RTT.
- Implement Caching: Caching frequently requested data closer to end-users can dramatically reduce the need for data to travel long distances. The result really helps with lowering RTT.
- Monitor and Troubleshoot: Regularly monitor your network for signs of congestion or packet loss. If issues arise, take steps to troubleshoot and resolve them promptly.
Discover ClouDNS Monitoring service!
RTT vs Latency
RTT and latency are related but not identical metrics in networking. Latency is the time it takes for a packet to travel from the source to the destination, often referred to as a one-way delay. RTT, on the other hand, measures the total time it takes for a packet to go to the destination and for a response to come back to the source.
It is important to mention that RTT is not always exactly twice the latency. Factors such as network congestion, processing delays at routers, and asymmetrical routing can cause RTT to differ from simply doubling the latency. For example, if the route from source to destination is more congested or longer in one direction, the round-trip time might be significantly higher than twice the latency.
Round-Trip Time (RTT) is the silent force that shapes our online experiences. From the seamless loading of web pages to the quality of our video calls, RTT plays a pivotal role in ensuring that digital interactions happen at the speed of thought. As we continue to rely on the Internet for work, entertainment, and communication, understanding and optimizing this metric will be crucial for both end-users and network administrators. By reducing it through strategies, we can have a faster, more responsive digital world where our online activities are limited only by our imagination, not by lag.

Hello! My name is Vasilena Markova. I am a Marketing Specialist at ClouDNS. I have a Bachelor’s Degree in Business Economics and am studying for my Master’s Degree in Cybersecurity Management. As a digital marketing enthusiast, I enjoy writing and expressing my interests. I am passionate about sharing knowledge, tips, and tricks to help others build a secure online presence. My absolute favorite thing to do is to travel and explore different cultures!

Related Posts

What is ICMP (Internet Control Message Protocol)?
July 17, 2024 • DDoS , Internet , Protocols
The ICMP (Internet Control Message Protocol) is a network layer protocol and also a supporting protocol in the Internet protocol suite. It ...

Ping Traffic Monitoring: Ensuring Network Health and Efficiency
March 28, 2024 • Monitoring
In an era where digital connectivity is the lifeline of businesses and individuals alike, maintaining optimal network performance is more ...

Ping of Death (PoD) – What is it, and how does it work?
December 5, 2023 • DDoS , Protection
Ping of Death sounds pretty scary, and it can bring down your server and keep it that way for an extended period of time using a simple ...

DNS Troubleshooting – tools and commands
October 19, 2023 • Tools
In the vast universe of network management and IT troubleshooting, issues related to the Domain Name System (DNS) often crop up. DNS is a ...
Leave a Reply Cancel reply
Your email address will not be published. Required fields are marked *
Recent Posts
- SMTP (Simple Mail Transfer Protocol) explained
- Botnet – what is it, and how does a Botnet attack work?
- Domain parking. What is it and why does it exist?
- What is SMTP Smuggling? How to detect and prevent it?
- What is Backup DNS?
- Cloud Computing
- DNS Records
- Domain names
- Load balancing
- SSL Certificates
- Uncategorized
- Web forwarding
- DNS Services
- Managed DNS
- Dynamic DNS
- Secondary DNS
- Reverse DNS
- DNS Failover
- Anycast DNS
- Email Forwarding
- Enterprise DNS
- Domain Names
- Monitor website traffic and optimize your user experience
- Evaluate which marketing channels are performing better
- Analyse aggregated data about usage of the website to understand our customers. Randomized identifiers shared with partners.
- Store your preferences from previous visits
- Collect user feedback to improve our website
- Evaluate your interests to provide you unique customised content and offers
- Make online and social advertising more relevant for you
- Invite specific customer groups to reconnect with our products later
- Share data with our advertising and social media partners via their third-party cookies to match your interests
Round Trip Time (RTT)
In the realm of network technology, there is a wealth of specialized terms and procedures. These elements pivotally support the smooth operation of the global Internet. Central among these is the concept of Round Trip Time (RTT). Understanding RTT is crucial for unraveling how data moves across networks, and its influence on the quality of online activities.

The term 'Round Trip Time', or RTT, denotes the timespan taken for a data unit to journey from its starting point to a specified destination and back. Simplistically put, it symbolizes the united timespan that includes signal transmission and the receipt of a responding signal. This counter-signal typically signifies successful acknowledgment of the original signal, dispatched from the destination back to the starting point.
RTT is a respected metric in network technology due to its profound impact on the efficiency and speed of data interchange. It serves as a 'heartbeat' of a network, determining critical attributes about its ongoing health and functional capacity.
Why RTT Matters
RTT matter extends beyond its capacity to measure time. It acts as a vital index of the performance of your network connection. A decreased RTT indicates speedy sending and reception of data packets, resulting in quick website content loading times, uninterrupted multimedia broadcasting, and reduced in-game network latency. Conversely, an increased RTT can result in Internet delays and a subsequent degraded user experience.
RTT: The Key Yardstick in Networking
RTT is pivotal in network technology as it is involved in multiple networking protocols like the Transmission Control Protocol (TCP) to direct the exchange of data packets amongst computer systems. For example, TCP uses RTT to specify the optimal waiting period for response receipt before it restarts data packet transmission. This approach minimizes repeated transmissions, thereby enhancing data buffering efficiency.
In conclusion, Round Trip Time (RTT) is a critical aspect of network technology. It measures how long a data chunk needs to travel from its origin to a selected spot and back. Familiarizing with this concept is vital for gaining insights into the workings of the Internet and strategies for boosting network performance. The subsequent sections delve deeper into RTT's intricacies, exploring its everyday implications for Internet usage, its significance in gaming, and its crucial role in network troubleshooting, among others.
Unraveling the Basics of RTT
RTT, acronym for Round Trip Time, underscores an imperative idea in the universe of networking. It specifically refers to the duration a chunk of data experiences during its travel from origin to endpoint, and returning back to the source. A comprehensive cognizance of this idea is instrumental in decoding the operational speed and dexterity of a network system.
Data Packet Transit: An Overview
A clear perception of RTT requires cognizance of the voyage undertaken by a data packet. When initiating a request online, such as prompting a hyperlink or sending an email, your device dispatches a chunk of data towards the server that hosts the desired website or emailing facility. This chunk of data, or packet, maneuvers through an array of routers and switches, each contributing a minor time incrementation to the overall journey. Upon the receipt of this packet, the server processes the request and generates a response that is directed back to your device. The complete duration taken for this travel constitutes the RTT.
Exploring RTT Components
RTT is an amalgamation of distinct elements. Initial element is propagation delay, reflecting the time consumption for a packet to move from origin towards its destination. The computation of this time duration takes into account the physical distance between the targeted points, aided by the pace of light within the medium, generally fiber optic cables.
The next element contributing to RTT is transmission delay, quantifying the duration for the data packet to gain physical entry onto the network. This duration is influenced by the packet size and the network's bandwidth capacity.
Additional elements include processing delay, highlighting the duration taken for a router or switch to handle the packet. This entails time taken for error identification and resolution, and routing.
The final ingredient in the RTT is queuing delay - the duration a packet spends in the queue awaiting processing by a router or switch, which is contingent upon the network's congestion status and the protocol-defined packet priority level.
RTT’s Function within TCP/IP
RTT acts as a significant clog in the mechanism of the Transmission Control Protocol/Internet Protocol (TCP/IP) - the basic internet protocol suite. TCP/IP utilizes RTT to ascertain the ideal window size favoring data upload and to formulate an accurate timeout duration for packets remaining unacknowledged.
Within TCP/IP, the Round Trip Time Estimator algorithm calculates the anticipated RTT (ERTT) grounded on the recently recorded RTT (MRTT) of previous packet transmissions. This mathematical computation follows the formula:
ERTT = (1 - α) ERTT + α MRTT
Here, α is a factor that oscillates between 0 and 1. The weightage of the recent RTT measurements is elevated in this formula, allowing the ERTT to adapt to the fluctuating network conditions.
Interplay of RTT and Ping
Measuring RTT is often conducted leveraging a tool such as ping. Activating ping directs a packet towards a defined destination, awaiting a desired response. The duration occurring between the dispatch and receipt of the packet equates to the RTT. Ping’s simplistic characteristics render it a capable instrument for RTT measurement and network issue identification.
In conclusion, RTT is a core evaluating factor for network efficiency determination. It encapsulates the duration experienced by a data packet from the moment of dispatch until its return journey. RTT plays an impactful role in the functionality of the TCP/IP protocol compliance. For those working alongside network or internet-centric technologies, an enriched understanding of RTT is crucial.
RTT in Daily Life: Everyday Examples
Our regular activities are intimately intertwined with a lesser-known concept, RTT (Round Trip Time). From emailing to gaming or video surfing, this underpinning principle becomes paramount in dictating your interaction's excellence. Let's illuminate this critical component with a few real-life illustrations.
Electronic Mail Exchange
Picture the journey of an email, fragmented into multiple data fragments, propelled across the internet stratosphere to land in the recipient's server. RTT fundamentally measures the span it takes for a single fragment to make a round trip between your system and the destination server. Elements of delay creep in with a high RTT, impacting the swiftness of your email delivery. Although this may appear inconsequential in standard exchanges, the ramifications are significant during time-critical correspondences.
Virtual Gameplay
In the virtual gaming universe, RTT becomes the invisible adjudicator of your experience. Every action you make, be it character motion or launching an attack, converts into data fragments moving towards the gaming server. This server digests this information before reciprocating a response. The chronology of this entire operation is termed RTT.
A low RTT manifests in a virtually instantaneous in-game reflection of your actions, creating a fluid, pleasurable gaming session. Conversely, a high RTT brings about an irritating delay or 'lag' between your maneuvers and in-game ramifications.
Digital Video Consumption
During a video playback, data fragments are in a constant relay from the content server to your gadget. RTT captures the timescale this fragment takes to make a return journey from the server to your device.
When RTT is minimal, you enjoy a smooth, non-stuttering video playback. But a high RTT gives rise to frequent halts due to buffering and a compromised video resolution, all because the data fragments are unable to match pace for a continuous video render.
Internet Surfing
Browsing the internet is essentially a practice of dispatching requests to respective web servers and receiving website data in return. RTT measures the timeframe for this exchange.
Reduced RTT ensures swift webpage rendering, enabling a fluid browsing experience. However, a high RTT translates to a sluggish loading speed, particularly noticeable when accessing data-intensive websites.
Therefore, RTT is an obscure key influencing our daily digital interactions. By grasping its function & impact, we can uncover the intricate mechanics empowering our online existence.
The Mathematics behind RTT: A Non-Complex Explanation

To parse the principles that are intertwined with Round Trip Time (RTT), one doesn't necessarily need to be a mathematician. Essentially, these principles are not beyond basic arithmetic and common sense. Here, we'll demystify the essentials.
Symbolic Representation
Think of RTT as a clock measuring the journey of a data packet as it moves from origin to destination and reintegrates into the origin. Its formulaic expression captures four distinct stages in this journey:
RTT = Journey Initiation Time + Travel Time + Waiting Time + Decoding Time
Here's a closer look at each of these phases:
- Journey Initiation Time: Envisage a highway with vehicles (data packages) rushing in at bursting speed. This time is essentially the span required for each vehicle to completely enter onto the highway. It's ascertained by the ratio of packet dimensions to the carrying capacity of the link.
- Travel Time: This second phase is about the transmigration of a single data fragment across the highway from the beginning to the endpoint. It's the ratio of the geographical gap between the two points to the speed of light in the transmission medium.
- Waiting Time: This is the time a data packet spends in line, waiting its turn to get processed. This duration can see significant fluctuations depending upon the pile-up on the highway.
- Decoding Time: It is the duration utilized by the routers and hosts to unravel the packet's identity from its header.
Sizing Implication on RTT
Packet or vehicle size plays a striking role in the dynamics of RTT. Higher dimensions lead to extended journey initiation and travel times, thus elevating RTT. Smaller sizes may pull down RTT but might simultaneously increase administrative load due to the swelling number of packets.
Bandwidth: A Key Player
Highway capacity or bandwidth can dramatically influence RTT. With more room to accommodate data, RTT drops. However, a greater bandwidth won't guarantee diminished RTT if traffic becomes overwhelming.
The Geographic Factor
The physical space between data sender and receiver fundamentally affects the travel time and hence the RTT. Expanded distances translate to increased RTT.
Network Traffic and RTT
The overall health of the highway, marked by scenarios like congestion and data loss, can substantially augment RTT. While congestion results in extended waiting duration, data loss necessitates re-dispatching of packets, thereby escalating RTT.
Let's emulate these ideas. Imagine a data unit of 1000 bytes in dimension, a highway of 1 Mbps bandwidth, a geographical gap of 1000 km between the sender and receiver, and light speed in medium measured at 200,000 km/s.
Deploying this input in the formula, we get:
- Journey Initiation Time = 1000 bytes * 8 bits/byte / 1 Mbps = 8 ms
- Travel Time = 1000 km / 200,000 km/s = 5 ms
- Considering negligible waiting and decoding times, the RTT equates to 8 ms + 5 ms = 13 ms.
This little illustration lights up our understanding of the rudimentary mathematics enmeshed within RTT. Mastering this knowledge can empower individuals to dissect the forces shaping RTT and how to manoeuvre it into achieving enhanced network output.
How RTT Impacts Your Internet Experience
As we venture into the digital wilderness, every device we use, be it a laptop, smartphone or a tablet, participates in a colossal information dance across the globe. This dance, which involves sending and receiving data, moulds the efficiency and smoothness of our online journey, with the Round Trip Time (RTT) operating as its intrinsic compass.
Decoding the Influence of RTT on Digital Experience
At the essence of RTT is the time an info-packet consumes to traverse from the initiation point (your gadget) to its terminus (the receiver server), and back. It’s a fundamental network barometer, intimately dictating the swiftness and reliability of your online connectivity.
Whenever you activate a weblink, dispatch an email or stream multimedia, your device is in a constant state of communication with the server that hosts the desired content. As the server returns the requested data, the clock ticks on this two-way journey - providing the RTT value.
A swift RTT translates into faster data transit, forging a slicker and fluid online journey. Conversely, a time-consuming RTT is responsible for frustrating hiccups such as buffering, lagging, and delays that could cripple your digital activities.
RTT’s Effect on Web Surfing
Think of the routine act of exploring a webpage. As you input a web address and press enter, your gadget shoots a request to locate and retrieve this webpage from its respective server. The server responds by sending the webpage details, which your browser converts into the visible screen content.
A time-intensive RTT slows down this relay race, potentially leading to delays and lag times. This becomes even more aggravating while navigating heavy-content platforms or multitasking across several tabs.
RTT’s Impact on Streaming Portals
Streaming platforms like Netflix, YouTube, and Spotify depend immensely on nimble RTTs to function seamlessly. As you enjoy a media file, your gadget is persistently soliciting additional data packets and receives them in return from the host server.
A sluggish RTT can trigger buffering lags as your device waits impatiently for data to land, placing unwanted interruptions in your streaming experience and causing potential dissatisfaction.
RTT and the Gaming Arena
Within the thrilling domain of online gaming, RTT could determine the victor and the fallen. Games mandate spontaneous interactions among players, and any communication delay can disturb the gaming rhythm.
A lethargic RTT time can instigate a lag – a noticeable and annoying lag between your gaming actions and the game’s reaction. In intense competitive gaming scenarios, every split second matters.
RTT and Virtual Meetings
In the contemporary remote work dynamics, video conferencing platforms such as Zoom and Microsoft Teams have become indispensable. Even these tools lean on efficient RTTs for uninterrupted, latency-free dialogues.
An elongated RTT may introduce delays in audio and visual inputs, potentially disrupting effective communication and causing potential confusion. This can have dire consequences in professional environments, where time is key, and clear dialogue is essential.
To manifest, RTT is an unsung hero shaping the quality of your digital interactions. A record low RTT time paves the way for a swift, efficient data relay, crafting a seamless online engagement. Contrarily, a slow RTT might introduce noticeable drags and disrupt your online immersion.
RTT in the World of Gaming: Making the Connection
In the digital sphere of gaming, each split-second is paramount. The deciding factor between triumph and defeat frequently rests on the pace and productivity of your network link speed. Here, the concept of Round Trip Time (RTT) becomes indispensable. Grasping the profound role of RTT can lead to maximizing your gaming prowess.
The Function of RTT in Virtual Gaming
When it comes to interactive gaming, RTT signifies the interval required for a data chunk to journey from your gaming unit (whether it's a console, desktop, or handheld device) towards the game host and return. This two-way journey is pivotal as it dictates the rapidity of your gaming response based on your controls and the maneuvers of other participants.
Take an example of you initiating a jump maneuver in the game, this instruction is relayed as a data chunk towards the game host. The host subsequently processes your instruction and reciprocates with a response, visualized on your interface. The entire time spent during this operation is your RTT.
RTT's Impact on Gameplay Quality
An optimized, low RTT translates to swift reaction times providing you an advantageous edge in adrenaline-pumping games where precision and speed hold the key. Conversely, a high RTT results in latency, prompting your game to respond lethargically.
This can be visualized using a first-person shooter game scenario. Sporting a high RTT, you take a shot at a rival but owing to the delay, the host logs your shot post the enemy's evasion, resulting in a miss. On the contrary, a minimal RTT records your maneuvers virtually instantaneously, providing you a realistic shot at the target.
RTT's Connection to Server Proximity
The geographical separation between your gaming equipment and the game host has substantial bearings on your RTT. Greater the distance to the host, the more time required for data chunks to complete their journey, culminating in a high RTT. It's no surprise that serious gaming enthusiasts gravitate towards hosts situated in close proximity.
RTT's Relationship with Network Traffic
Network traffic too has a pivotal role in defining your RTT. If your network is swarmed by numerous devices attempting simultaneous internet access, it curbs the data chunks' travel speed, resulting in an amplified RTT.
Quantifying RTT during Gaming
Almost all virtual games provide an avenue to verify your RTT or latency period. This is often illustrated in the game's configuration or flashed on the interface amid the gameplay. By vigilantly tracking your RTT, you can take corrective measures to reduce it when warranted, like shutting down bandwidth-consuming applications or opting for a proximal host.
In conclusion, RTT is of paramount significance in virtual gaming, wielding influence over your game's operational speed and your gaming session's quality. An awareness of RTT operations enables you to finely tune it, ensuring a competitive edge and enhancing your gaming enjoyment.
Network Diagnostics and RTT: A Deep Dive
Investigating network functions is pivotal for preserving and boosting the efficiency of a network. An instrumental index utilized in these probes is the Round Trip Time (RTT), which we'll expound on. We will dissect the interaction between RTT and network probes to offer a thorough insight into its value in resolving network complications and bolstering network operations.
Dissecting Network Probes
Network probes are an organized method applied to discover, isolate, and rectify issues connected to the network. They incorporate a succession of evaluations and verifications to study the network's functioning, pinpoint problem areas, and apply appropriate solutions. These evaluations could span from elementary ping evaluations to intricate scrutiny of network traffic.
Influence of RTT in Network Probes
RTT has a prominent role in network probes, delivering helpful data on the network functionality by calculating the duration needed for a data packet to journey from the origin to the endpoint and return. Extended periods for RTT regularly signify network pile-up, substantial latency, or alternative efficiency complications.
RTT and Efficient Network Operations
RTT is a reliable measure of network efficiency. A lesser RTT signifies an operational network with little latency, whereas an elevated RTT implies possible problems, for instance, network pile-ups or malfunctioning hardware. With RTT monitoring, network administrators can detect and tackle these issues swiftly, thus guaranteeing best network operations.
RTT and Network Problem-solving
RTT also aids considerably in network problem-solving. By comparing varying RTT values of separate network segments, operators can accurately locate a network issue. For example, repeated high RTT values in a specific segment could suggest an issue in that exact segment.
Instruments to Determine RTT
Several mechanisms can calculate RTT, each with their distinctive attributes and capabilities. A few often-used tools are:
- Ping : This basic command-line function dispatches an ICMP echo request to an assigned host and anticipates a response. The duration needed for the response to arrive is the RTT.
- Traceroute : This mechanism calculates the RTT needed for each step along the route from the origin to the endpoint. It aids in identifying the specific network segment responsible for high RTT rates.
- Network probes software : These all-encompassing tools offer real-time monitoring of network functionality, encompassing RTT. Examples of these tools consist of SolarWinds Network Performance Monitor and PRTG Network Monitor .
Techniques to Boost RTT
Boosting RTT is essential for improving network operations. Some of the strategies applied include:
- Load balancing : Apportioning network traffic across numerous servers can alleviate overload and lessen RTT.
- Quality of Service (QoS) : Giving priority to certain types of traffic can guarantee they encounter lower RTT.
- Route optimization : Selecting the shortest paths for data packet travels can minimize RTT.
In summary, RTT is a central measure in network probes. It offers crucial insights into network operations and assists in problem-solving. By accurately calculating and boosting RTT, operators can corroborate seamless and effective network operations.
Understanding Packet Travel and its Relation to RTT

The world of virtual transactions mandates a deep comprehension of the voyage adopted by data morsels. This signifies the path these morsels embark on while traversing from one endpoint to another via an internet grid, an intriguing journey, to say the least. This intricate path comprises numerous phases such as the encasing of data, broadcasting of signals, tracing the path, and ultimately unmasking at the intended endpoint. These phases attribute to the overall duration documented for a complete two-way trip (RTT) – a crucial metric of a network's operational competence.
Delineating the Expedition of Data Segmentations
Emphasizing the link between RTT and the motion of data segmentations involves an exploration of this voyage. As data disseminates over a grid, it disintegrates into minute parts labeled 'segmentations.' Each of these segmentations then obtains a protective coating of cardinal identifiers and trailing notes housing essentials about the origin, endpoint, and the correct order of the segmentation.
Initiated next is the travel over the grid for these fortified segmentations. The blueprint of the grid, coupled with the tangible stretch between the initiator and the receiver, outlines the quantity of routers and toggles the segmentations navigate through. Every device on the course scrutinizes the segmentation's identifiers to pinpoint the optimal pathway to the final destination.
On arrival at their destination, these segmentations shed their protective casings, and the introductory message undergoes reconstitution. The transmission process is announced successful if all segmentations arrive in the correct sequence, free of any anomalies.
How Segmentations Movement Influences RTT
The Round Trip Time (RTT) mirrors the comprehensive duration a data segmentation spends journeying from its origin, reaching the receiver, and retracing its path. It offers an insight into network delay or latency. An escalated stretch covered by the segmentation amplifies the RTT, subsequently depreciating the network’s efficiency.
A variety of elements could sway RTT during the segmentation's voyage:
- Dispatch Span: The duration expended in freeing the segmentation from its source to the endpoint. It is reliant on the segmentation's volume and the network's bandwidth. Vast segmentations and meager bandwidths culminate in extended dispatch spans and an escalated RTT.
- Signal Span: The essential duration for a signal to transit from the initiator to the receiver. It leans heavily on the geographical expanse and signal propagation speed. Extensive distances and slower velocities can trigger extended signal spans and an increased RTT.
- Computation Span: The duration a router or toggle takes to process each segmentation. The intricacy of the routing operation and the machine's efficacy show direct correlation. Complicated routes and inefficient machines inject lengthier computing spans, thereby escalating RTTs.
- Queue Span: The waiting duration a segmentation endures in a queue before getting addressed by a router or toggle. It pivots on network traffic. Overburdened networks result in lengthened queue spans and thus, higher RTTs.
Grasping these dynamics empowers network custodians to employ strategies to better segmentation traffic and minimize RTT, hence escalating network competence.
Drawing Parallels: Segmentations' Movement and RTT
The following matrix distinguishes the connection between segmentations' movement and RTT:
These findings reveal that each facet influencing segmentation movement correlates to its impact on RTT. Hence, enhancing segmentations' motion is fundamental in curbing RTT, thereby augmenting network efficiency.
To encapsulate, acquiring thorough knowledge of segmentation advancement and its connection with RTT is indispensable for those tasked with refining network movement or efficiency. Focusing on the factors that influence both segmentations' movement and RTT can enable proactive steps towards enhancing network operations, ensuring a seamless and efficient data exchange process.
RTT in Relation to Network Speed and Efficiency
Network performance and user satisfaction are paramount in the networking arena, highly dependent on two prime parameters: pace and proficiency. One pivotal component shaping these features is the Round Trip Time (RTT).
Unveiling Direct Impact of RTT on Network Pace
Essentially, RTT measures the time it needs for a data chunk to voyage from its origin, reach the destination, and return. The length of this tour mirrors the pace of your network. Lower RTT is synonymous with faster networks, hinting that data chunks are making their journeys quicker than usual. Conversely, elevated RTT levels correspond to languid networks - data chunks take an unusually long time to complete their round trips.
Here's a deciphered table to comprehend the essence:
Thus, Connection X, having the shortest RTT, exceeds in speed, while Connection Z, carrying the heaviest RTT, lags behind.
Unraveling Indirect Impact of RTT on Network Proficiency
RTT not only sets the pace but also molds the proficiency of a network. How effectively a network utilizes its resources to relay data chunks from origin to destination is its proficiency. Elevated RTT levels can stretch the waiting time for acknowledgement of the data chunks sent. Throughout this span, the sender stays dormant, sending no fresh data chunks, causing a gap in network potential. Such scenarios frequently arise in protocols like TCP relying on acknowledgments to steer data flow.
However, a contracted RTT lets the sender grab the acknowledgements quicker, permitting more data chunk transmission in the same span. This maximizes network potential, therefore enhancing proficiency.
Below is a clearer depiction:
In the end, RTT stands as a crucial determinant of the pace and proficiency of a network. Networks with lower RTTs race towards speed and proficiency, while those with higher RTTs lag. Hence, decoding and controlling RTT sits at the core of network performance enhancement.
Latency vs RTT: Essential Differences and Comparisons

Untangling the Web: Probing Network Functionality with a Focus on Delay and Complete Cycle Time (CCT)
Delay and Complete Cycle Time (CCT) are elemental factors that chiefly shape the efficacy of a network’s operation. While they are frequently interconnected, each presents separate facets of network data migration .
Clarifying Network Delay
Visualize network delay as a digital sand timer counting down fractions of a second. It shows the span needed for a data packet to travel from its initial source to its finishing destination within a network — a lightning-fast sprint from point A to point B, with the distance gauged in milliseconds (ms).
Factors such as the physical gap between the sender and the receiver nodes, the mode of data delivery (be it copper wires, fiber threads, or airwaves), along with the integration of multiple network components can affect this interval.
In-depth Analysis of Complete Cycle Time (CCT)
Conversely, CCT represents a full roundtrip — picture it as driving from your abode (point of departure), touring a botanical garden (final stop), and then heading back home (starting point). This accounts for the complete time investment needed for the roundtrip plus the waiting period at the stopover, along with the return to the onset. The CCT is proportional to the delay for the timing reflected in milliseconds (ms).
Separating Delay from CCT
These temporal facets are significant in detecting anomalies in network tasks. Typically, the swiftness of a network gets represented by delay, whereas the responsiveness gets determined by the CCT. Occasionally, a network might exhibit low delay, yet necessitate an extended period to wrap up a full cycle due to hold-ups and response lags at endpoints (high CCT).
Link between Delay and CCT
It’s vital to realize that CCT will invariably be on par with or surpass the delay. The CCT calculates the span consumed by data packets during a return trip, inclusive of surplus data handling time.
In theory, in a flawless network, the CCT would amount to twice the delay. However, practical complications like network interference, route hurdles, and traffic in network equipment generally cause the CCT to exceed twofold the span of the one-way journey.
Fundamentally, delay and CCT, while interconnected, divulge exclusive details for assessing network productivity. A keen comprehension of these disparities can markedly hone one’s proficiency in handling network-related intricacies with superior accuracy and productivity.
How to Measure RTT Accurately for Optimal Performance
The efficiency of web infrastructures is inherently determined by the accurate evaluation of its Data Turnaround Time (DATT), a crucial criterion used by IT specialists to detect and mend underperforming networks, enhance network output, and ensure a seamless working environment for end-users.
Constructing a Procedure for DATT Calculation
Observing DATT necessitates a rigorous analysis of the entire course a data unit navigates, from inception to termination. Given this task typically, transmission procedures such as ICMP (Inter-Network Communication Evaluation System) or TCP (Transmission Regulation System) are deployed. The major approaches used to scrutinize DATT include:
1. Echo Command : Among the prevalent techniques for measuring DATT is the 'echo' command. This sequence dispatches an ICMP echo plea to a predetermined site, and the infrastructure anticipates a reply. The duration taken to get this reply establishes the DATT value. Implement the echo command as such:
The outcome displays the DATT in milliseconds (ms).
2. RouteTrack Command : A viable addition to Echo, the 'routetrack' command lets you peep into the track a data unit covers and separately displays the DATT for each lap of its journey. Execute the routetrack command like this:
This will dissect the individual DATTs for each leg of the data unit's journey.
Undetectable Factors that Might Misinterpret DATT Calculations
Unrecognizable variables that may misrepresent DATT evaluations encompass:
- Surge in Network Consumption : An abrupt leap in network usage may lead to data unit stacking, thereby extending the DATT.
- Geographical Extent : The physical distance separating the source and the endpoint can augment DATTs due to extended transfer periods.
- Device Potency : The sufficiency and robustness of the tools used to create and gather data can also distort DATT calculations.
Sophisticated Instruments for Accurate DATT Estimation
For precise DATT estimates, Network supervisors can employ these universally acknowledged instruments:
- CybernetScope : Renowned for its extensive prowess in network procedure inspection, CybernetScope can analyze and display data unit DATTs.
- EchoMapper : This progressive apparatus combines 'echo' and 'routetrack' functionalities into a visual and intuitive depiction.
- VirtuNet : VirtuNet offers DATTs together with an array of comprehensive network performance markers.
Ensuring Dependable DATT Outputs
To retain reliable DATT outputs:
- Frequent Verification : Conduct multiple inspections at varied intervals to cross-verify network inconsistencies.
- Review of Network Consumption : Schedule assessments during peak and off-peak traffic slots for a balanced evaluation.
- Dependable Methods : Use extensively acknowledged tools known for their efficacy in DATT calculation.
In the final analysis, a precise appraisal of DATT enables IT gurus to ensure maximum network output. Adequate probing techniques, recognition of misleading variables, and the application of tried-and-tested tools are critical determinants in ascertaining a network's top-tier performance.
Techniques for Reducing and Controlling RTT
Pursuing an optimal online journey? Managing and trimming down Round Trip Time (RTT) is a paramount consideration. In this context, we'll explore a multitude of methodologies designed to thresh out this objective.
Grasping the Importance of RTT Trimming
It's favorably beneficial to comprehend the vital underpinnings of why RTT reduction is of supreme importance. Mile-high RTT measurements may retard network competency, impinging activities from web surfing to E-sport challenges and media broadcasting online. By constraining RTT, we are able to exponentially boost the online experiences.
Approach 1: Refining Network Apparatus
Carving the inaugural step towards RTT attenuation involves refining network apparatus. This consolidation consists of assuring optimal performance of all network devices, comprising of routers and switches. Periodic fine-tuning and upgrades can support this pursuit.
Additionally, the spatial configuration of the network might influence the RTT. To illustrate, an overextended network covering a vast geographical region will inherently possess an escalated RTT compared to networks confining to a smaller area. Hence, orchestrating the network configuration with a focus on RTT minimization can aid its reduction.
Approach 2: Deploying Content Delivery Networks (CDNs)
Deploying Content Delivery Networks (CDNs) are formidable in curtailing RTT. CDNs function by cacheing a website's content on an assemblage of servers dispersed globally. If a user petitions to view a webpage, the content is expedited from the nearby server, effectively diminishing the RTT.
Approach 3: Leveraging TCP Window Scaling
TCP Window Scaling is a technique that can aid in trimming down RTT in networks with towering bandwidth-delay product (BDP). Expanding the TCP window size allows an increase in the amount of unconfirmed data that can be transmitted before an acknowledgment is required, thus curbing RTT.
Approach 4: Pathway Refinement
Pathway refinement entails the selection of the most beneficial route for data packets to traverse from source to destination. Opting for the shortest and least congested route can contribute to significant RTT reduction.
Approach 5: Protocol Streamlining
Disparate protocols bear different RTTs. Such as, TCP commonly has a higher RTT compared to UDP . Therefore, protocol selection can play a vital role in RTT reduction by choosing the apt protocol for the requirement.
Approach 6: Deploying Condensation Techniques
Utilizing condensation methods may assist in shrinking the volume of data transmitted, thus restricting RTT. It should be highlighted, however, that condensation can also enhance processing time, thus a careful cost-benefit analysis is essential.
Approach 7: Controlling Buffer Bloating
Buffer bloating is a scenario where superfluous buffering of data packets elevates latency and jitter, additionally decreasing overall network pace. Taming this phenomenon can help in curtailing RTT.
To wrap up, managing and constraining RTT embraces diverse strategies, ranging from refining network apparatus and activating CDNs, to streamlining communication protocols and controlling buffer bloating. By activating these approaches, we can potentially uplift the online experiences comprehensively.
The Impact of RTT on Video Streaming and VoIP Calls
In the digital world, our dependence on advanced tech tools, such as online video streaming and internet-based calls (VoIP), is tremendous. The effectiveness of these tools is directly reliant on robust and rapid internet connections. The network's Round Trip Time (RTT)- the time taken for data packets to travel from source to destination and back, is a significant determinant of their performance.
Insights on RTT's Influence on Online Video Streaming
Our everyday activities often involve the exchange of video data, whether we're binge-watching TV shows on Netflix, gaining knowledge from YouTube educational content, or engaging in live chats on Facebook. The quality and reliability of these platforms are significantly affected by RTT.
When a video begins to stream, data packets take a journey from the origin server to the viewer's gadget. The complete circuit followed by these packets, from their origin to destination and return, constitutes the RTT. A high RTT implies a greater delay in data packet delivery, causing irritations such as continuous buffering or lagging, which drastically compromises the viewing experience.
In contrast, a lower RTT means faster connectivity, contributing to an uninterrupted streaming journey. Therefore, ensuring a minimal RTT is key to top-notch digital entertainment experience.
The Bearing of RTT on VoIP Calls
Similarly, RTT largely impacts the quality of VoIP calls. In a VoIP call, verbal communications are converted from analog signals into digital data packets, which are then dispersed across the network.
The effectiveness of a VoIP call is strongly dictated by its RTT. A high RTT has the potential to cause substantial audio transmission delays, resulting in undesirable effects like echoes or overlapping speeches. Such disruptions hinder the natural flow of conversation and induce user dissatisfaction.
On the other hand, a smaller RTT ensures an audible and realistic voice quality, resembling conventional telephone call experiences. Hence, lower RTT is essential for flawless VoIP communication.
Drawing Parallels: Effects of RTT on Video Streaming and VoIP Calls
How to Reduce RTT for Optimal Video Streaming and VoIP Calls Experience
Various methods can be employed to curtail RTT and enrich your video streaming and VoIP call experiences:
- Choose a wired network : Generally, a wired (cable) connection yields lower RTTs than a wireless one.
- Upgrade your internet package : A superior bandwidth package can substantially reduce RTT.
- Use a server in close geographical reach : Selecting a server near your location often culminates in a smaller RTT.
- Utilize Quality of Service (QoS) tools : QoS tools can prioritize certain network activities, thereby reducing RTT for video streaming and VoIP calls.
In summary, RTT significantly affects the experience of video streaming and VoIP calls. Understanding this fact and implementing strategies to minimize it can dramatically enhance users' online communication experiences.
RTT in Wireless Networks: An In-depth Analysis
Wireless networks have become our invisible companions, silently fuelling our digital existence, be it at home, work, or cafes. Yet, they leave us in a lurch when poorly performing, often attributed to factors like Round Trip Time (RTT).
Decoding RTT in Wireless Setups
Simply put, RTT is the full circle time a data packet takes from origin to the end-point and back to the origin. It's a barometer of various influencing elements such as network density, distance between data source and recipient, radio wave disturbances, and signal power.
Imagine streaming your favorite movie in an overpopulated café with numerous devices jostling for Wi-Fi. The network density escalates, leading to higher RTT. Likewise, connecting to the Wi-Fi from your garden might lead to weakened signals due to distance, further escalating RTT.
RTT's Impression on Wireless Network Efficiency
RTT propels a domino effect on the quality of wireless productivity. Imbalanced RTT triggers sluggish data movement, souring the digital experience. Streaming or gaming with escalated RTT is the culprit behind intermittent buffering or lagging.
In contrast, regulated RTT is the assurance of brisk data movement, promising uninterrupted, pleasurable digital navigation.
The Puppeteers of RTT in Wireless Ecosystems
- Distance: A stretched distance between sender and receiver expands the data packet's journey, inflating RTT.
- Network Density: A jam-packed network, bustling with multiple users or data packets, clutters the gateway, amplifying RTT.
- Radio Wave Disturbances: Any electronic equipment interfering with the wireless signal can deviate the signal, leading to augmented RTT.
- Signal Power: A feeble signal intensifies RTT since the data packets frequently miss the reception, triggering retransmission.
Estimating RTT in Wireless Ecosystems
Tools like the "ping" are your allies to gauge RTT in wireless environments. It propels a data packet to a designated IP and records the round trip time.
For example, on a Windows system, activate the Command Prompt, input "ping www.google.com", and the outcome will register the RTT time stamp in milliseconds.
Diminishing RTT in Wireless Ecosystems
Here are some tactics that can help mitigate RTT in wireless setups:
- Router Placement: An ideally placed router, preferably central and obstruction-free, boosts the signal strength.
- Minimizing Network Jam: Scrimping on device connectivity can help ensure fluid network traffic and deflate RTT.
- Dual-Band Router Utilization: Such routers can shift between two frequencies, mitigating interference and thereby lowering RTT.
- Updating Network Assets: Integration of contemporary networking assets and technology can enhance network quality, pushing down the RTT.
To sum up, understanding and handling RTT can make or break your wireless network’s efficiency. Harnessing knowledge about RTT, its influencers, estimation techniques, and mitigation strategies can help you sculpt an optimized, high-performance wireless network.
RTT: A Critical Factor in Telecommunications
Gauging network efficiency in telecommunications is incumbent upon a key metric known as the Bidirectional Transit Duration (BTD). This component significantly modifies and shapes the system's output, a relationship we will explore alongside its interaction with distinctive communication models, and how adept BTD control plays a definitive role in yielding superior performance.
BTD: An Indispensable Parameter in Telecommunication Platforms
To decode telecommunication jargon, Bidirectional Transit Duration or BTD refers to the time taken for the successful journey of data from its genesis to the allocated endpoint and back. Its impact in telecommunication processes is immeasurable as its influence is directly proportional to the pace and efficiency of data dispersion. Hence, a compressed BTD duration implies an amplified data transmission speed which triggers an enhancement in the quality of communication.
BTD serves as an indispensable yardstick assessing the performance of the network within the foundations of telecommunication infrastructure. This enables the identification and timely mitigation of impending issues, thus optimizing network function to superior stages. For instance, an elevated BTD can be indicative of network overloading, obligating administrative intervention for apt adaptations.
Repercussion of BTD on Protocols for Communication
Numerous communication guidelines experience the profound impression of BTD. Consider the example of Communication Regulation Protocol (CRP). This protocol depends on BTD to determine the most flexible volume designated for data exchange. In this setting, the term 'volume' denotes the quantity of data that can be dispatched without the requirement for acknowledgement of receipt from the recipient's end. By modulating this volume in accordance with BTD parameters, CRP can facilitate uninterrupted exchange of data, thus averting any possible bottlenecks.
Tailoring BTD for Luxuriant Performance
Exemplary telecommunication output warrants proficient BTD control. This includes regular monitoring of BTD values, noting deviations, and initiating rectifying procedures.
- BTD Parameter Observation : Diurnal BTD observation can pinpoint potential network issues. Instruments like Axial Monitor and Navigation Tracker can be availed for this purpose.
- Deviation Monitoring : A remarkable shift from the typical BTD values can portend possible network issues. For instance, a sudden surge in BTD could be indicative of network bottlenecks or malfunctioning equipment.
- Adaptation Initiatives : Once the anomaly is detected , immediate curative steps need to be taken. Such actions may encompass rerouting of traffic channels, upgrading system hardware or modifying network settings.
To encapsulate, BTD has yielded itself indispensable, imposing a paramount influence in the realm of telecommunications, bearing a pronounced effect on its output and productivity. By maintaining a stringent measure on BTD, telecommunication service providers can ensure unrivalled service, consequently refining user experience.
How RTT Shaped the Internet: A Historical Perspective
RTT (Round Trip Time) has been instrumental in the transformation of the internet throughout the ages. A deeper study of RTT's influence on successive internet modifications aids our understanding of its comprehensive evolution.
RTT: The Catalyst for Advanced Network Functionality
In the early part of internet history, functioning under the aegis of the Advanced Research Projects Agency Network (ARPANET), RTT held a vital value. Here, communication happened through fragmenting data into small packets, which then traveled via the network. The time consumed for one such packet to travel from origin to endpoint and again to the origin— denoted as RTT — became an imperative parameter of network proficiency.
During the infancy period of ARPANET, the RTT values were considerably high due to rudimentary technologies and structural limitations. Gradual technology advancements subsequently curtailed the RTT values, promoting quicker and more effective networks.
RTT: Stepping Stone to the TCP/IP Epoch
The introduction of Transmission Control Protocol/Internet Protocol (TCP/IP) in the 80s marked a significant stride in the internet's chronicle. TCP/IP utilized RTT to control the speed of data transfer and avert probable network traffic jams — predicaments crucial to sustaining network regimentation and efficiency.
Using a specialized algorithm, TCP/IP modulated the data transmission speed based on RTT values. A soaring RTT value signified network congestion, which directed a reduction in data transmission to circumvent packet loss. In contrast, a lower RTT value indicated an unfettered network passage, thereby accelerating data transmission.
RTT: Guiding Light in the WWW Phase
The advent of the World Wide Web in the 1990s underscored the relevance of RTT. As websites started adopting graphic illustrations, multimedia components, and interactive modules, both the size of data packets and RTT saw an uptick.
However, continuous scientific developments combined with infrastructural improvements managed to regulate the RTT. The inception of Content Delivery Networks (CDNs) specifically mitigated the RTT values by repetitively hosting web content in diverse locations— thereby reducing data packet travel distances.
RTT in Today's Internet World
In today's interconnected world, RTT remains crucial for network efficacy. As we witness an etiolation in the utilization of bandwidth-demanding applications like cloud computing, video broadcasting, and digital gaming, the need for least possible RTT has magnified many folds.
Currently, Internet Service Providers (ISPs) and network overseers employ cutting-edge methods and apparatuses to gauge and enhance RTT. This is done to offer the least possible RTT, ensuring a hiccup-free user experience.
In summary, the journey of the internet from the ARPANET phase to the current interconnected era has been hugely influenced by RTT. The level of RTT's influence on internet modifications and feasibility is immense. With forthcoming technological breakthroughs like 5G and the Internet of Things (IoT) , RTT's relevance is envisaged to escalate even further.
Future of RTT: Trends and Predictions
As the digital world evolves, Round Trip Time (RTT) remains a crucial gauge in determining network efficiency. With entire societies increasingly dependent on the internet for information exchange or corporate logistics, network speed and accuracy are paramount. It's in this backdrop where RTT is continually scrutinized for network productivity and troubleshooting bottlenecks.
5G and its Correlation with RTT
A significant milestone in the communication sphere is the advent and deployment of 5G networks. These networks pledge remarkable speed and minimal latency, potentially reducing RTT and positively influencing data transfer and network productivity.
5G networks anticipate a latency rate of approximately one millisecond, a massive leap from the 50-millisecond latency rate exhibited by 4G networks. This dramatic dip in latency will invariably lower RTT, securing faster data interchange and enhanced network productivity.
Despite these promising features, 5G will not eradicate RTT. The data transfer sequence from the origin to recipient and vice versa is inescapable, requiring a time allotment. Hence, while 5G significantly diminishes RTT, its monitoring and management are unarguably necessary.
IoT’s Influence on RTT
Internet of Things (IoT), with its proliferating devices linked to the internet, could affect RTT. IoT might elevate RTT since the network may be hard-pressed to manage escalating traffic due to the exponential data exchange increase.
Despite this, IoT devices usually work on low power and exchange minimal data, thus alleviating potential stress on RTT. Coupled with breakthroughs in network technology such as edge computing, these factors facilitate RTT reduction as data is processed closer to origin, thus shrinking the travel radius.
Incorporating AI in Micro-managing RTT
Artificial Intelligence (AI) , another transforming trend, could significantly decimate RTT. AI, with its automation capacity, could redefine network management by mechanizing RTT monitoring and optimization.
AI's capability to scrutinize network traffic tendencies and predict probable RTT hikes serves as an ingenious tool. Network managers could leverage this information to take preemptive actions such as redirecting traffic or escalating bandwidth prior to RTT becoming a significant issue.
In essence, the factors shaping RTT's future are varied, including 5G deployment, IoT expansion, and AI integration. Nonetheless, RTT stays a decisive gauge for network productivity assessment. Therefore, accurately deciphering and micro-managing RTT is a skill that network managers and IT practitioners must hone.
Case Studies: The Effect of RTT on Major Corporate Networks
In the sphere of business communication systems, we can often overlook the impact of Round Trip Time (RTT). Yet, the evidence from different scenarios has reflected the considerable role that RTT plays in shaping the functionality and productivity of these systems. This chapter explores a number of such practical examples illustrating the importance of RTT within the digital infrastructure of large-scale businesses.
Illustrative Example 1: International Banking Corporation
An International banking corporation, operating in more than 50 nations, reported fluctuating network performance issues. Initially, the corporation's information technology specialists suggested that lack of sufficient bandwidth was for the inconsistency. A comprehensive examination, however, revealed an elevated RTT was the main reason.
Capable of managing an enormous flow of digital information, the corporation's network started having issues due to increased RTT, the result of geographical diversity of its operations. High RTT led to problems with the TCP window size, inadequately utilizing the existing bandwidth.
The corporation enforced several modifications to cut down on RTT, such as enhancing routing protocols and enacting Quality of Service (QoS) guidelines. This remedial action markedly improved the network performance - a testament to RTT’s vital effect on network productivity.
Illustrative Example 2: Online Retail Behemoth
An online retail behemoth catering to a worldwide clientele encountered difficulties with its website's response time. Regardless of a solid infrastructure and sufficient bandwidth, the company’s website response time fell below the set industry norms, particularly for clients located remotely from its server base.
After thorough research, the main reason behind the extended response time was identified as high RTT; with each HTTP request from the client’s browser needing to cover a significant distance to reach the corporation’s servers, thus creating a high RTT.
In order to rectify this problem, the company put a Content Delivery Network (CDN) into operation which reduced the physical space between clients and servers, consequently mitigating the RTT. This move considerably enhanced the website’s response time, emphasizing the integral role of RTT in ensuring a smooth user experience.
Illustrative Example 3: Transnational Software Conglomerate
A transnational software conglomerate, with a scattered workforce, faced trials with its in-house communication applications. In spite of having access to a rapid internet connection, its workforce faced delays during video calls and VoIP communications.
The IT team of the conglomerate realized the issue wasn't with the internet speed but the high RTT. The data packages were travelling long distances to reach the receivers, causing a high RTT and subsequent delays in communication.
The conglomerate dealt with this problem by deploying edge computing, moving data processing closer to the source, and thus reducing RTT. This adjustment enhanced the quality of video calls and VoIP discussions, emphasizing the influence of RTT on instantaneous communication.
These practical examples illustrate RTT's vast role in shaping the functionality and productivity of business communication systems. They also emphasize the necessity of precise evaluation and control of RTT for optimal network performance. As businesses continue their expansion on a global scale, RTT will play an increasingly pivotal role in shaping their digital communication experiences.
The Role of RTT in Internet Troubleshooting
When wading through the maze of the web, both regular netizens and tech savants may occasionally hit a snag. During these moments, bearing witness to the potency of the Round Trip Time (RTT) metric can be a revelation. RTT is instrumental in tackling problematic internet connectivity, ensuring a smooth, proficient handling of interruptions.
Pegging Network Problems: RTT's Decisive Duty
Essentially, RTT is the time taken for a packet of data to be dispatched from its source, reach its desired destination, and return. The insights derived from RTT can offer a wealth of information about the performance and operation status of a network.
Stumbled over a cyber hurdle? RTT fills the role of an efficient mechanic, isolating problems like high latency, disappearing data packets, and network congestion. If you notice your RTT scores skyrocketing, that could mean the network’s speed is deteriorating. Sudden, drastic alterations in RTT could indicate fluctuating network stability or obstructions.
Interpreting the Link between RTT and Network Efficiency
RTT's influence on network performance is paramount. A lower RTT denotes a speedy, high-functioning network. In contrast, a sky-high RTT implies the opposite. By evaluating RTT, cybersecurity experts can home in on and iron out network kinks.
Any unexpected hike in a network's RTT might originate from excessive network traffic, hardware snags, or hiccups with the Internet Service Provider (ISP). Recognizing the seeds of an inflated RTT is the initial step in overcoming these hurdles and bolstering network efficiency.
Tracking Disappearing Data Packets: RTT's Role
One common cyber conundrum is the loss of data packets during transmission, resulting in imperfect or delayed data delivery. RTT can be employed as a trustworthy auditor to root out this issue by highlighting discrepancies in data packet transmission timelines.
Persistently high RTT could indicate vanishing or delayed packets due to overburdened networks, hardware hang-ups, or ISP-specific headaches. Identifying and methodically correcting these elements could lead to noticeable enhancements in network performance.
The Symbiosis Between RTT and Network Traffic Jams
When networks are overwhelmed with data deluge, it can manufacture hold-ups and disruptions in data transference, often manifested as escalated RTT values and errant packets.
IT wizards can tackle these complexities by vigilantly monitoring RTT. For instance, a sharp upswing in RTT during high traffic periods might signify network congestion. Well-planned strategies like bandwidth allocation or traffic routing could come in handy in distributing network workload fairly and preventing system overwhelm.
RTT as a Technological Troubleshooter: A Real-life Example
Consider the scenario of an internet user tormented by sluggish connections and sporadic disconnections. They could conduct a basic ping test, leveraging RTT to clock the time lapse between their device and the server.
Consistent, high RTT could suggest network malfunctions. Users can investigate potential culprits like network bottlenecks, hardware hitches, or ISP-induced glitches. Pinpointing and eliminating the triggers behind such escalated RTT can enhance their internet speed and stability.
To sum up, RTT is a powerful tool when it comes to identifying, analysing and resolving internet challenges. It offers vital data about network functions, while also assisting in identifying and rectifying issues like severe latency, packet losses, and network blockages. By wielding RTT intelligently, everyday web users and IT pros can experience secure, nimble, and consistently high-performing internet connectivity.
What is round-trip time (RTT) and how to reduce it?

Round-trip time (RTT) is the time it takes for the server to receive a data packet, process it, and send the client an acknowledgement that the request has been received. It is measured from the time the signal is sent till the response is received.
When a user clicks a button on a website, the request is sent to the server as a data packet. The server needs time (RTT) to process the data, generate a response, and send it back. Each action, like sending a form upon a click, may require multiple requests.
RTT determines the total network latency and helps monitor the state of data channels. A user cannot communicate with the server in less than one RTT, and the browser requires at least three round trip times to initiate a connection:
- to resolve the DNS name;
- to configure the TCP connection;
- to send an HTTP request and receive the first byte.
In some latency-sensitive services, e.g., online games, the RTT is shown on the screen.

- Factors affecting RTT
Distance and number of intermediate nodes. A node is a single device on the network that sends and receives data. The first node is the user’s computer. A home router or routers at the district, city, or country level are often intermediate nodes. The longer the distance between the client and server, the more intermediate nodes the data must pass through and the higher the RTT.
Server and intermediate node congestion. For example, a request may be sent to a fully loaded server that is concurrently processing other requests. It can’t accept this new request until other ones are processed, which increases the RTT. The RTT includes the total time spent on sending and processing a request at each hop, so if one of the intermediate nodes is overloaded, the RTT adds up.
You never know exactly to what extent the RTT will grow based on how the infrastructure is loaded; it depends on individual data links, intermediate node types, hardware settings, and underlying protocols.
Physical link types and interferences. Physical data channels include copper, fiber optic, and radio channels. The RTT here is affected by the amount of interference. On the Wi-Fi operating frequency, the noise and other signals interfere with the useful signals, which reduces the number of packets per second. So, the RTT is likely to increase over Wi-Fi than over fiber-optics.
- How to calculate RTT using ping
To measure the RTT, you can run the ping command in the command line, e.g., “ping site.com.”

Requests will be sent to the server using ICMP. Their default number is four, but it can be adjusted. The system will record the delayed time between sending each request and receiving a response and display it in milliseconds: minimum, maximum, and average.
The ping command shows the total RTT value. If you want to trace the route and measure the RTT at each individual node, you can use the tracert command (or traceroute for Linux or Mac OS). It is also can be performed via the command line.
- Normal RTT values
Many factors affect RTT, making it difficult to establish a normal—the smaller the number, the better.
In online games, over 50 milliseconds are noticeable: players cannot accurately hit their targets due to network latency. Pings above 200 milliseconds matter even when users browse news feeds or place online orders: many pages open slowly and not always fully. A buyer is more likely to leave a slow website without making a purchase and never come back, which is what 79 percent of users do .
Let’s compare the pings of the two sites—the US jewelry store Fancy and the German news portal Nachrichtenleicht.de . We will ping them from Germany.

The RTT of a German news portal is almost three times lower than that of a US store because we ping from Germany. There are fewer nodes between the user and the server, which are both in the same country, so the RTT is lower.
- How to reduce RTT
Connect to a content delivery network (CDN). The hosting provider’s servers are usually located in the same region where most of the audience lives. But if the audience of the site grows or changes geographically, and content is requested by users who are far away from the server, RTT increases for them, and the site loading speed is slower. To increase the loading speed, use a CDN.
CDN (Content Delivery Network) is a service that caches (mostly static) content and stores it on servers in different regions. Therefore, only dynamic content is downloaded from the main source server, which is far from the user. Heavy static files—the main share of the website—are downloaded from the nearest CDN server, which reduces the RTT by up to 50 percent.

For example, the client requests content from a CDN-connected site. The resource recognizes that there is a caching server in the user’s region and that it has a cached copy of the requested content. To speed up the loading, the site substitutes links to files so that they are retrieved not from the hosting provider’s servers, but from the caching server instead since it is located closer. If the content is not in the cache, CDN downloads it directly from the hosting server, passes it to the user, and stores it in the cache. Now a client on the same network can request the resource from another device and load the content faster without having refer to the origin server.
Also, CDN is capable of load balancing: it routes requests through redundant servers if the load on the closest one is too high.
Optimize content and server apps. If your website has visitors from different countries/regions, you need a CDN to offset the increased RTT caused by long distances. In addition, the RTT is affected by the request processing time, which can be improved by the below content optimizations:
- Audit website pages for unnecessary scripts and functions, reduce them, if possible.
- Combine and simplify external CSS.
- Combine JavaScript files and use async/await keywords to optimize their processing—the HTML code first, the script later.
- Use JS and CSS for individual page types to reduce load times.
- Use the tag instead of @import url (“style.css”) commands .
- Use advanced compression media technologies: WebP for images, HEVC for video.
- Use CSS-sprites: merge images into one and show its parts on the webpage. Use special services like SpriteMe.
- I want to reduce RTT with CDN. What provider to choose?
For fast content delivery anywhere in the world, you need a reliable CDN with a large number of points of presence. Try Gcore CDN —this is a next-generation content delivery network with over 140 PoPs on 5 continents, 30 ms average latency worldwide, and many built-in web security features. It will help to accelerate the dynamic and static content of your websites or applications, significantly reduce RTT, and make users satisfied.
Table of contents
Try gcore cdn, related articles, 5 ways to improve website speed for e-commerce, what website speed is and why it matters for e-commerce success, how to spot and stop a ddos attack, improve your privacy and data security with tls encryption on cdn, how edge ai solves 5 ai inference workload challenges, real-life applications of low-latency edge inference, what is serverless computing, what is webassembly (wasm), subscribe to our newsletter.
Text to modify
Explore all Obkio features
Network Performance Monitoring
Measured between two locations
Network Devices
Device performance via SNMP Polling
Traceroutes
Identify where the issue is located
Networks & Applications
SD-WAN Monitoring
Internet performance monitoring, voip monitoring, mpls monitoring, uc monitoring.
Network Metrics
Packet Loss Monitoring
Latency monitoring, network speed monitoring, mean opinion score monitoring, jitter monitoring, bandwidth monitoring, throughput monitoring, qos monitoring, network audit, continuous monitoring, obkio vs other solutions.
Discover why Obkio outshines other solutions.
For small and large enterprise
Educational
For college and universities
For single and home offices
Testimonials
See what some of our clients have to say
Case Studies
Real stories from Obkio's clients
Managed Service Provider
Helps MSPs quickly fix network problems
Your Source for In-Depth Network Monitoring Knowledge
Get A Free Demo
White Papers
Download free guides on performance monitoring
In-Depth Webinars, Step-by-Step Walkthroughs, and More
Screenshots
Detailed screenshots from Obkio's app
- Documentation
Technical documentation about onboarding, support, feature guides, and training.
Last Blog Post

How to monitor Network Performance: A Simple Guide
- Try for Free
- Contact sales
Success Stories
- Contact Sales
Understanding & Reducing Network Round-Trip Time (RTT in Networking)
Table of contents.
In the dynamic realm of modern business operations, the heartbeat of connectivity relies on the seamless flow of information across networks. Network administrators and IT professionals, entrusted with the pivotal responsibility of maintaining these vital lifelines, understand the significance of every nanosecond.
In a world where time equates to money and efficiency is non-negotiable, the RTT in networking emerges as a pivotal metric. It represents the time taken for a packet of data to travel from its source to its destination and back again, reflecting the responsiveness and effectiveness of your network infrastructure. As businesses increasingly rely on cloud-based applications, remote collaboration tools, and real-time data analytics, the optimization of RTT has become more critical than ever.
In this comprehensive exploration, we will decode the intricacies of Network Round-Trip Time, demystifying its importance and empowering network administrators and IT professionals with actionable insights to reduce RTT and enhance network performance.
What is Network Round-Trip Time (RTT in Networking)?
First, let’s make sure we’re all on the same page.
Network Round-Trip Time (RTT) in networking, also commonly referred to as Round-Trip Latency or simply Latency, is a crucial metric that measures the time it takes for a packet of data to travel from its source to its destination and back again to the source . RTT is typically expressed in milliseconds (ms) and is a fundamental aspect of network performance.
Here's a breakdown of what RTT encompasses:
- Transmission Time : This is the time it takes for a packet of data to travel from the sender to the receiver. It includes the propagation time (the time it takes for the signal to physically travel through the network medium) and the processing time (the time it takes for routers, switches, and other network devices to handle the packet).
- Propagation Delay : This is the time it takes for an electrical or optical signal to travel over the physical medium, such as a copper or fibre-optic cable. Propagation delay depends on the distance the signal needs to cover and the speed of light or electricity in the medium.
- Queuing and Processing Delay : As data packets pass through routers and switches in a network, they may spend some time in queues waiting for their turn to be processed. This queuing and processing delay can vary based on network congestion and the efficiency of network devices.
In summary, Network Round-Trip Time (RTT) is a key metric in networking that measures the time it takes for data to travel from its source to its destination and back, encompassing transmission time, propagation delay, and queuing/processing delay. It plays a significant role in determining the responsiveness and efficiency of networked applications and services.

The Role of RTT (Network Round-Trip Time) in Network Responsiveness
Network responsiveness, often measured by RTT, is the cornerstone of user satisfaction and efficient operations.
RTT is a critical factor in network performance because it directly impacts the responsiveness of network applications and services. Low RTT values indicate that data can travel quickly between endpoints, resulting in faster response times for applications and a more seamless user experience. On the other hand, high RTT values can lead to delays and sluggish performance.
Reducing RTT is essential in scenarios where real-time communication, online gaming, video conferencing, or the timely delivery of data is crucial. Network administrators and IT professionals often work to optimize RTT by employing various strategies such as using content delivery networks (CDNs), minimizing network congestion, and optimizing routing paths.
- User Expectations : Today's users have high expectations for network responsiveness. Whether it's loading a web page, streaming a video, or making a VoIP call, users demand minimal delays. A low RTT ensures that users experience quick response times, leading to seamless and satisfactory interaction with applications and services.
- Real-Time Applications : Many critical business applications, such as video conferencing, online collaboration tools, and financial trading platforms, require real-time data exchange. RTT directly impacts the effectiveness of these applications. A shorter RTT means that data reaches its destination faster, enabling real-time interactions without noticeable delays.
I. Network Round-Trip Time (RTT) and User Experience
User experience is a key driver of customer satisfaction and loyalty. RTT plays a pivotal role in shaping this experience.
- Website Performance : For businesses with an online presence, website performance is paramount. A website with low RTT loads quickly, ensuring that visitors can access information, make purchases, or engage with content without frustrating delays. Studies have shown that longer page load times due to high RTT can result in higher bounce rates and decreased conversions.
- Video and Media Streaming : In an era of video marketing and content consumption, RTT directly influences the quality of video streaming. Lower RTT values mean faster buffer-free streaming, enhancing the viewer's experience and reducing the likelihood of video interruptions.
II. Network Round-Trip Time’s (RTT) Impact on Business Operations
Beyond user experience, RTT has a profound impact on various aspects of business operations:
- Productivity : In a remote or hybrid work environment, where employees rely on cloud-based applications and data access, RTT can significantly impact productivity. Sluggish network performance due to high RTT values can lead to frustration, downtime, and decreased efficiency.
- Data Transfer : Businesses often need to transfer large volumes of data between locations or to the cloud. High RTT can lead to slow data transfer speeds, potentially affecting data backup, disaster recovery, and the ability to access critical information in a timely manner.
- Customer Service : For businesses that provide customer support or run call centers, low RTT is essential for clear and uninterrupted VoIP calls. High RTT can lead to call dropouts, poor call quality, and dissatisfied customers.
- E-commerce : In the world of e-commerce, where every millisecond counts, RTT can impact sales and customer retention. Slow-loading product pages and checkout processes due to high RTT values can result in abandoned shopping carts and lost revenue.
Understanding the significance of RTT in modern networking is not just a technical matter; it's a fundamental aspect of delivering a positive user experience, maintaining productivity, and ensuring the seamless operation of critical business processes. Network administrators and IT professionals must prioritize RTT optimization to meet the demands of today's digital business landscape.
Ready to Optimize Your Network's Round-Trip Time? Try Obkio Today!
Are you eager to take control of your network's performance and reduce Round-Trip Time (RTT) to boost productivity and enhance user experiences? Look no further than Obkio's Network Performance Monitoring tool, the ultimate solution for network administrators and IT professionals.

Why Choose Obkio:
- Real-Time Monitoring : Obkio provides real-time visibility into your network, allowing you to identify latency bottlenecks and pinpoint performance issues as they happen.
- User-Friendly Interface : With an intuitive and user-friendly interface, Obkio makes it easy to monitor your network's RTT and other critical metrics without the need for complex configurations.
- Actionable Insights : Obkio offers actionable insights and recommendations to help you optimize your network's performance, reduce RTT, and ensure seamless business operations.
- Customized Alerts : Set up custom alerts to be notified of performance deviations, ensuring that you can proactively address issues before they impact your users.
Unlock the Full Potential of Your Network with Obkio. Get Started Today!
Don't let network latency hold your business back. Take the first step towards optimizing your network's Round-Trip Time and providing an exceptional user experience. Try Obkio's Network Performance Monitoring tool now and experience the difference.

Measuring and Calculating Network Round-Trip Time: How to Calculate RTT
While understanding the significance of RTT is vital, the ability to quantify and interpret it accurately is equally crucial for network administrators and IT professionals.
In this section, we’ll equip you with the knowledge and tools necessary to measure, calculate, and make sense of RTT metrics effectively. RTT measurement is not merely a technical exercise; it's a strategic endeavour that empowers you to fine-tune your network for peak performance, deliver an exceptional user experience, and ensure the seamless operation of critical business processes.
So, join us as we explore the RTT formula, discover the range of tools at your disposal for RTT measurement, and learn the art of interpreting RTT metrics.
I. Understanding the Network RTT Formula
The RTT formula is a fundamental concept for anyone aiming to measure and manage network latency effectively. It provides a straightforward way to calculate the Round-Trip Time between two endpoints in a network.
The formula for RTT is as follows:
RTT = (t2 - t1) + (t4 - t3)
- t1 : The time at which the sender sends the packet.
- t2 : The time at which the sender receives an acknowledgment (ACK) from the receiver.
- t3 : The time at which the receiver receives the packet.
- t4 : The time at which the receiver sends the ACK back to the sender.
Understanding this formula allows you to measure RTT manually by recording these timestamps. In practice, however, RTT is often measured automatically using specialized tools and software.
I. Tools for Measuring Network RTT
Accurate RTT measurement is crucial for network administrators and IT professionals. Fortunately, a range of tools and methods are available to simplify this process:
- Network Monitoring Software : Comprehensive network monitoring solutions, such as Obkio's Network Performance Monitoring tool , offer real-time RTT measurement and historical data tracking. These tools provide insights into RTT trends, allowing you to identify performance fluctuations and optimize network resources.
- Ping : The ping command is a simple and widely used tool for measuring RTT. It sends ICMP echo requests to a destination and records the time it takes for responses to return. While ping provides basic RTT information, it may not be suitable for more detailed analysis.
- Traceroute : Traceroute is another command-line tool that helps you trace the path a packet takes to reach its destination. It provides information about each hop along the route, including RTT values. Traceroute is useful for diagnosing latency issues and identifying bottlenecks in the network.
- Packet Analyzers : Packet analyzers like Wireshark capture network packets and provide detailed analysis, including RTT calculations. They are invaluable for diagnosing complex network issues but require a deeper understanding of packet-level data.
- Cloud-Based Monitoring Services : Cloud-based services can measure RTT from multiple locations globally, offering a broader perspective on network performance. These services often include user-friendly dashboards and alerting features.

III. Interpreting Network RTT Metrics
Interpreting RTT metrics is essential for making informed decisions about network optimization. Here's how to understand the data:
- Baseline RTT : Establish a baseline RTT for your network under normal operating conditions. This baseline serves as a reference point for identifying deviations and potential issues.
- Variability : Monitor the variability of RTT values over time. Consistently high or fluctuating RTT can indicate network congestion, equipment problems, or other performance bottlenecks.
- Comparing RTT Metrics : Compare RTT metrics between different endpoints, routes, or network segments. This can help pinpoint specific areas of concern and prioritize optimization efforts.
- Thresholds and Alerts : Set RTT thresholds and network monitoring alerts to be notified when latency exceeds acceptable levels. Proactive alerting allows you to address performance issues before they impact users.
- Root Cause Analysis : When RTT metrics indicate performance problems, use additional tools and diagnostics to perform a root cause analysis. Isolate the source and causes of latency and implement corrective measures.
Interpreting RTT metrics effectively empowers network administrators and IT professionals to make data-driven decisions, optimize network performance, and deliver a seamless user experience.
In conclusion, understanding the RTT formula, utilizing measurement tools, and interpreting RTT metrics are essential steps in managing and improving network latency. These skills enable network professionals to diagnose issues, identify opportunities for optimization, and ensure efficient network performance.
IV. How to Calculate RTT in Networking: An Example
Let's walk through a simple example of calculating Network Round-Trip Time (RTT) for a packet of data travelling between two devices.
Suppose you have a sender ( Device A ) and a receiver ( Device B ) connected to the same network. You want to measure the RTT for a packet of data sent from Device A to Device B and back.
Here are the key timestamps you'll need to measure or record:
- t1 : The time at which Device A sends the packet.
- t2 : The time at which Device A receives an acknowledgment (ACK) from Device B.
- t3 : The time at which Device B receives the packet.
- T4 : The time at which Device B sends the ACK back to Device A.
Now, let's assume the following timestamps:
- t1 : 12:00:00.000 (Device A sends the packet)
- t2 : 12:00:00.150 (Device A receives the ACK from Device B)
- t3 : 12:00:00.200 (Device B receives the packet)
- t4 : 12:00:00.350 (Device B sends the ACK back to Device A)
Now, you can use the RTT formula to calculate the Round-Trip Time:
Plug in the values:
RTT = (12:00:00.150 - 12:00:00.000) + (12:00:00.350 - 12:00:00.200)
RTT = 0.150 seconds + 0.150 seconds
RTT = 0.300 seconds
So, in this example, the calculated Network Round-Trip Time (RTT) for the packet travelling between Device A and Device B is 0.300 seconds, or 300 milliseconds (ms).
This RTT value represents the time it took for the data packet to travel from Device A to Device B and back, including the time it spent in transit and the time it took for the acknowledgment to return.
In this article, we explore the importance of testing network latency for businesses and provide tools and techniques for accurately measuring latency.
How to Measure Network Round-Trip Time with NPM Tools
When it comes to measuring and optimizing Network Round-Trip Time (RTT), Network Performance Monitoring (NPM) tools are your go-to.
NPM tools provide real-time visibility into network performance and continuously and comprehensively monitor various aspects of a network, allowing network administrators to track RTT metrics at multiple points in the network infrastructure.
By offering a granular view of RTT, NPM tools help identify performance bottlenecks, allowing for swift diagnosis and targeted optimization. Additionally, NPM tools often include alerting features that notify administrators when RTT exceeds predefined thresholds, enabling proactive problem resolution before end-users experience the impact.
Moreover, NPM tools are equipped with historical data analysis capabilities, allowing network professionals to identify trends and patterns in RTT values. By identifying long-term RTT patterns, administrators can make informed decisions about capacity planning, infrastructure upgrades, or routing optimization to ensure consistent low-latency network performance.
In a world where network responsiveness is crucial for user satisfaction and business productivity, NPM tools are invaluable for network administrators and IT professionals aiming to maintain optimal RTT and deliver a seamless user experience. Let’s learn how to deploy them!
Step 1. Deploy A Network Performance Monitoring Tool with RTT Monitoring Features
High RTT can lead to delays and sluggish network performance - but how can you know the extent of the problem?
The most accurate way to measure RTT and other key network metrics is by using a Synthetic Network Performance Monitoring Software, like Obkio.
Unlike standalone RTT monitoring tools, Obkio provides a holistic approach to network performance analysis, making it the best choice for measuring RTT and network performance as a whole. With Obkio, gain access to real-time monitoring and reporting features that allow them to measure RTT across their entire network infrastructure, including routers, switches, and end-user devices.
This end-to-end network monitoring tool not only identifies RTT issues but also provides valuable insights into latency, packet loss, bandwidth utilization and more.
Obkio continuously measures network metrics like network RTT by:
- Using Network Monitoring Agents in key network locations
- Simulate network traffic with synthetic traffic and synthetic testing
- Sending packets every 500ms to measure the round trip time it takes for data to travel
- Catch RTT and other network issues affecting key applications and services
Step 2. Measure Round-Trip Time in All Network Locations
Persistent and erratic spikes in Network Round-Trip Time (RTT) measurements are indicative of substantial performance challenges within your network, demanding immediate attention. To pinpoint and resolve these irregularities, implementing RTT monitoring is an indispensable step.
Obkio’s Network Monitoring Solution will measure RRT and other network metrics by sending and monitoring data packets through your network every 500ms using Network Monitoring Agents . The Monitoring Agents are deployed at key network locations like head offices, data centers, and clouds and continuously measure the amount of time it takes for data to travel across your network.
This is extremely important when monitoring RTT and addressing spikes to maintain network efficiency and a smooth user experience, especially in scenarios where real-time data exchange, applications, and services are critical.
For example , you can measure network RTT between your head office and the Microsoft Azure cloud, or even between Azure and your data center.
To deploy monitoring in all your network locations, we recommend deploying:
- Local Agents : Installed in the targeted office location experiencing performance issues or latency spikes. There are several Agent types available (all with the same features), and they can be installed on MacOS, Windows, Linux and more.
- Public Monitoring Agent : These are deployed over the Internet and managed by Obkio. They compare performance up to the Internet and quickly identify if the performance issue is global or specific to the destination. For example, measure RTT between your branch office and Google Cloud .

Step 3. Measure Round-Trip Time for Network Devices
Network Device Monitoring is also crucial for accurately measuring and managing Network Round-Trip Time (RTT). Network devices, such as routers, switches, and firewalls, play a significant role in determining the latency and RTT experienced by data packets as they traverse the network.
Obkio’s Network Device Monitoring feature is a fast and easy solution to get detailed information about the health of your core network devices. Used with the end-to-end Network Performance Monitoring feature, Network Device Monitoring with SNMP Polling helps IT teams quickly and proactively pinpoint issues with devices like firewalls, routers, switches and Wi-Fi access points.
Network devices are key points of control and routing within a network. Monitoring these devices allows you to gain insights into their performance, such as how efficiently they process and forward data packets. Device monitoring helps identify issues like high CPU utilization, memory constraints, or network interface errors, which can all contribute to increased RTT.
Here are the key network devices you should consider monitoring when measuring network round-trip time:
- Routers : Routers are pivotal devices in network traffic management. They determine the path data packets take between networks and subnetworks. Monitoring routers helps identify congestion points, routing issues, and overall device performance.
- Switches : Network switches are responsible for forwarding data packets within a local network (LAN). Monitoring switches helps ensure that LAN traffic is efficiently handled and doesn't introduce unnecessary RTT.
- Firewalls : Firewalls are essential for network security but can also introduce latency. Monitoring firewalls helps verify that they're processing data packets efficiently and not creating undue RTT delays.
- Load Balancers : Load balancers distribute network traffic across multiple servers or resources to ensure load distribution and fault tolerance. Monitoring load balancers helps maintain even traffic distribution and low RTT.
- Gateways : Gateways connect different networks, such as LANs to the internet. Monitoring gateways is essential for ensuring data packets are efficiently routed between internal networks and external destinations.
- WAN Optimization Devices : These devices are commonly used in wide-area networks (WANs) to reduce latency and optimize data transfer. Monitoring WAN optimization devices ensures they're operating as intended to minimize RTT.
- Access Points (APs) : In wireless networks, APs play a critical role in data transmission. Monitoring APs helps maintain consistent wireless network performance, minimizing RTT for mobile or remote users.
- DNS Servers : DNS (Domain Name System) servers translate domain names into IP addresses. Monitoring DNS servers ensures that DNS resolution doesn't introduce delays when clients access network resources.
- Network Endpoints : Monitoring the performance of endpoints (e.g., servers, workstations, and user devices) is vital for understanding how network devices affect RTT from the user's perspective.
- Virtualization and SDN Controllers : In virtualized or software-defined networks, controllers manage network resources and routing. Monitoring these controllers helps ensure efficient data flow and low RTT.
To comprehensively measure and optimize RTT, it's essential to monitor a variety of network devices . The choice of devices to monitor may depend on the specific characteristics of your network and the critical points for your organization.

Step 4. Collect Network Round-Trip Time Measurements
Once you’ve set up your Monitoring Agents for network latency monitoring , they continuously measure metrics like RTT measure and collect data, which you can easily view and analyze on Obkio’s Network Response Time Graph.
Measure RTT throughout your network with updates every minute. This will help you understand and measure good round-trip time measurements for different applications vs. poor latency. If your RTT levels go from good to poor, you can also further drill down to identify exactly why RTT issues are happening, where they’re happening, and how many network locations they’re affecting.
To more accurately measure RTT in your network, and receive alerts when latency measurements are poor, Obkio sends alerts based on historical data and not just static thresholds.
As soon as there’s a deviation in the historical data, and your network is experiencing poor RTT measurements, Obkio sends you an alert.
It’s as simple as that
Step 5. Monitor More Network Metrics Alongside Network Round-Trip Time
Once deployed, Obkio’s Monitoring Agents will begin exchanging synthetic traffic to continuously measure network performance and core network metrics .
When monitoring network performance and assessing the health of your network, it's important to measure a range of network metrics alongside Network Round-Trip Time (RTT) to gain a comprehensive understanding of the network's behaviour and potential issues. Here are several key network metrics to consider:
- Packet Loss : Packet loss indicates the percentage of data packets that fail to reach their destination. High packet loss can significantly impact the quality of network services and applications.
- Jitter : Jitter is the variation in latency or RTT. Consistent RTT values are desirable, but high jitter can lead to unpredictable network performance, which is problematic for real-time applications like VoIP and video conferencing.
- Bandwidth Utilization : Monitoring bandwidth usage helps you identify periods of congestion and overutilization, which can lead to increased RTT. By monitoring bandwidth, you can proactively manage network capacity.
- Throughput : Throughput measures the rate at which data is transmitted over the network. It's essential for assessing the actual data transfer capacity of your network, especially for large file transfers or media streaming.
- Error Rate : The network error rate indicates the number of data packets with errors or corruption. High error rates can lead to retransmissions, increasing latency and packet loss.
- QoS Metrics : Quality of Service (QoS) metrics include parameters like latency, jitter, and packet loss, specific to certain traffic types. Monitoring QoS compliance is essential for prioritizing critical applications and ensuring they meet performance requirements.
- Device Performance : Monitoring the performance of network devices such as routers, switches, and firewalls is crucial. High CPU usage , memory issues, or hardware problems can impact network performance and increase RTT.
- Availability and Uptime : Monitoring network availability and network uptime is essential for identifying periods of network unavailability or downtime, which can impact services and applications.
By measuring these network metrics alongside RTT, you can gain a holistic view of your network's performance, detect issues promptly, and proactively optimize network resources to provide a seamless user experience and support critical business operations.

Understanding Good vs. Bad Network Round-Trip Time Measurements
In the intricate world of networking, the metric known as Network Round-Trip Time (RTT) serves as a crucial barometer of performance. However, RTT is not a one-size-fits-all metric, and its evaluation must be tailored to the specific needs and demands of a network or application.
In this section, we delve into the nuanced realm of RTT measurements, deciphering what constitutes good and bad readings, and how these metrics reverberate through the fabric of network performance.
Good and bad RTT measurements are relative and depend on the specific context and requirements of a network or application. What is considered good or bad RTT can vary based on factors such as the type of network, the application's sensitivity to latency, and the expectations of users. However, here are some general guidelines to consider:
I. Good Network RTT Measurements
- Low and Consistent : Good RTT measurements typically exhibit low and consistent values. Low RTT indicates that data is transmitted quickly, providing a responsive user experience. Consistency ensures that users can rely on predictable network performance.
- Match Application Requirements : Good RTT measurements should meet or exceed the requirements of the applications and services being used. For example, real-time applications like video conferencing or online gaming often require RTT values below 100 milliseconds to provide a seamless experience.
- Minimal Jitter : Good RTT measurements have minimal jitter, meaning that there is little variation in RTT values. Jitter can disrupt real-time applications, so a stable and low-latency network is desired.
II. Bad Network RTT Measurements:
- High and Fluctuating : Bad RTT measurements typically exhibit high values and significant fluctuations. High RTT values can lead to sluggish network performance and application responsiveness, while fluctuations introduce unpredictability.
- Exceed Application Tolerances : For some applications, any RTT values beyond specific thresholds can be considered bad. For example, an online multiplayer game might become unplayable with RTT exceeding 200 milliseconds.
- Frequent Packet Loss : Consistent packet loss and retransmissions can lead to bad RTT measurements. Packet loss is a sign of network congestion or instability, and it can severely impact network performance.
- Long-Term Performance Issues : Consistently bad RTT measurements over an extended period, even if they are not extremely high, may indicate underlying network issues that need to be addressed. It's essential to identify and resolve long-term performance problems to maintain a reliable network.
In summary, good RTT measurements are characterized by low, consistent values that meet the requirements of the network's applications, with minimal jitter. Bad RTT measurements, on the other hand, involve high, fluctuating values, packet loss, and latency that exceeds application tolerances. To assess RTT measurements, it's important to consider the specific network requirements and the impact of latency on user experience in your particular environment.

Identifying, Troubleshooting, and Common Network Round-Trip Time (RTT) Issues
In the world of networking, Network Round-Trip Time (RTT) serves as a vital performance indicator. When RTT issues arise, they can lead to sluggish network responsiveness and user dissatisfaction. This section is your guide to identifying and troubleshooting common RTT problems that can affect network performance.
We'll dive into the practical aspects of recognizing RTT issues, whether through real-time monitoring or user feedback. We'll also explore the common culprits behind elevated RTT, such as congestion and configuration problems.
I. Identifying Network RTT Issues
- Real-time Monitoring : Regularly monitor RTT using network performance monitoring tools, like Obkio NPM . These tools provide real-time data on RTT, enabling you to detect anomalies or spikes that might indicate issues.
- Baseline Measurement : Establish a baseline for expected RTT values in your network. Deviations from this baseline can be an early indicator of RTT problems.
- User Feedback : Listen to user complaints or feedback. Slow application response times or connectivity issues reported by users can be indicative of RTT issues.
- Historical Analysis : Analyze historical RTT data to identify patterns or trends. Consistent RTT issues at specific times or on particular network segments can point to the source of the problem.
- Network Topology Review : Examine your network topology to identify potential bottlenecks or congestion points that may contribute to high RTT.
II. Uncovering The Most Common Network RTT Issues
- Network Congestion : Heavy network traffic can lead to network congestion , queuing delays, and packet loss, resulting in increased RTT. Implement Quality of Service (QoS) to prioritize essential traffic and reduce congestion.
- Long Geographic Distance : Data travelling over long distances, especially in wide-area networks (WANs), can experience high propagation delay, contributing to elevated RTT. Consider implementing content delivery networks (CDNs) to reduce the impact of distance.
- Hardware and Configuration Problems : Outdated or misconfigured network devices, such as routers and switches, can lead to performance issues and high RTT. Regularly review and update hardware and configurations to address these problems.
- Packet Loss : Packet loss , where data packets are dropped or need to be retransmitted, can increase RTT. Troubleshoot packet loss issues by identifying and rectifying network faults or congestion points.
- Jitter : Inconsistent RTT values and jitter can affect real-time applications. Jitter is often a result of network congestion or configuration problems, so minimizing these issues helps reduce jitter and improve RTT.
III. Troubleshooting Network RTT Issues:
So what happens when your NPM tool starts alerting you about sudden spikes in round-trip time? Well, it’s time to troubleshoot! First, you need to understand why the network issue is happening, where and when.
- Isolate the Problem : Start by identifying the affected network segment or path with high RTT. Network monitoring tools can help pinpoint the problematic area.
- Traffic Analysis : Analyze the network traffic on the identified segment to determine if congestion or unusual patterns are causing high RTT.
- Device Inspection : Examine the performance of network devices along the path, such as routers and switches. High CPU usage or configuration errors may be contributing to RTT issues.
- Quality of Service (QoS) Adjustment : If network congestion is the root cause, consider implementing or adjusting QoS policies to prioritize critical traffic and reduce congestion.
- Optimization Techniques : Implement optimization techniques such as route optimization, network load balancing , and the use of CDNs to improve network efficiency and reduce RTT.
- Testing and Validation : After making adjustments, conduct tests to validate that RTT has improved. Monitor the network to ensure that RTT remains within acceptable ranges.
- Regular Maintenance : Ongoing network maintenance, including updates, hardware upgrades, and configuration reviews, is essential for preventing future RTT issues.
By systematically identifying, troubleshooting, and addressing RTT issues, network administrators can maintain low-latency networks, ensure a seamless user experience, and minimize the impact of common RTT problems.
Learn how to troubleshoot network issues by identifying where, what, why network problems occur with Network Troubleshooting tools.
Factors Affecting Network Round-Trip Time (RTT)
As we navigate the realm of Network Round-Trip Time (RTT) and its role in network optimization, we encounter an array of influential factors that shape the journey of data from source to destination and back. In this chapter, we embark on a comprehensive exploration of these key factors, each wielding the power to either elevate or hinder network performance.
Understanding the factors affecting RTT is paramount for network administrators and IT professionals, as it equips them with the knowledge needed to fine-tune their networks for maximum efficiency and responsiveness.
1. Network Congestion on RTT in Networking
Network congestion occurs when there is a higher volume of traffic on a network than it can efficiently handle. This congestion can significantly impact RTT:
- Increased Latency : Congestion leads to packet queuing, where data packets must wait in line to be processed by network devices. The increased latency due to this queuing results in higher RTT values, causing delays in data transmission.
- Packet Loss : In congested networks, packets may be dropped to relieve congestion. This packet loss not only contributes to higher RTT as packets are retransmitted but also affects the reliability and performance of network applications.
- Quality of Service (QoS) : Implementing Quality of Service policies can help mitigate congestion by prioritizing certain types of traffic. This can help ensure that critical applications experience lower RTT values even during network congestion.
2. Geographic Distance on RTT in Networking
Geographic distance plays a fundamental role in determining RTT, especially in wide-area networks and global connectivity:
- Propagation Delay : As data travels over long distances, it experiences propagation delay. This delay is the time it takes for signals to traverse the physical medium (e.g., fibre-optic cables or satellite links) between network endpoints. The greater the distance, the higher the propagation delay, contributing to increased RTT.
- WAN vs. LAN : Wide Area Networks ( WANs ) typically involve greater geographic distances than Local Area Networks ( LANs ). WANs often exhibit higher RTT values due to the inherent challenges of data transmission across extensive physical distances.
- Use of Content Delivery Networks (CDNs) : CDNs can help mitigate the impact of geographic distance by caching and delivering content from servers closer to end-users. This minimizes the effects of long-distance transmission on RTT.
3. Network Hardware and Configurations on RTT in Networking
The hardware and configuration of network devices and infrastructure can significantly affect RTT:
- Router and Switch Performance : The processing capacity of routers and switches in the network can impact the speed at which packets are forwarded. Outdated or underpowered devices can introduce additional latency and increase RTT.
- Network Path Efficiency : The chosen network paths and routing algorithms also play a role. Inefficient routing can lead to longer paths and, subsequently, higher RTT.
- Configuration Errors : Misconfigurations in network devices, such as incorrect routing tables or Quality of Service settings, can lead to suboptimal performance and increased RTT. Regular network audits and optimization are essential to address configuration issues.
4. Packet Loss and Jitter on RTT in Networking
Packet loss and jitter are network phenomena that can cause variations in RTT:
- Packet Loss : Packet loss occurs when data packets fail to reach their intended destination. Repeated packet loss results in retransmissions, which contribute to increased RTT. Reducing and measuring packet loss through network optimization is essential for minimizing RTT.
- Jitter : Jitter refers to the variation in packet arrival times. Excessive jitter can cause fluctuations in RTT, affecting the predictability of network performance. QoS mechanisms and traffic shaping can help mitigate jitter-related RTT issues.
Understanding these factors and their impact on RTT is crucial for network administrators and IT professionals. By addressing these challenges through proactive network management, optimization, and the use of appropriate technologies, it's possible to achieve lower RTT and maintain efficient and responsive network performance.

Network Round-Trip Time (RTT) vs. Latency: Comparing Network Siblings
In the world of networking and data transmission, terms like "Network Round-Trip Time (RTT)" and "latency" often take center stage, reflecting the critical aspect of speed and responsiveness in today's digital landscape. While these terms are sometimes used interchangeably, they represent distinct facets of network performance.
In this section, we’ll unravel the differences between Network Round-Trip Time (RTT) and latency. Understanding these concepts is fundamental for network administrators and IT professionals as it enables them to grasp the nuances of network performance and address specific challenges effectively.
I. Defining Latency
Latency is a general term that refers to any delay or lag in data transmission within a network . It encompasses all delays encountered during data communication, including the time it takes for data to travel between two points (which is what RTT specifically measures), as well as other types of delays such as processing delays, queuing delays, and transmission delays.
Latency can be categorized into several types:
- Propagation Delay : The time it takes for a signal or data packet to physically travel over the network medium (e.g., copper cables, fibre-optic cables, or wireless links). It is directly related to the distance between two network points and the speed of the medium.
- Transmission Delay : The time it takes to push the entire data packet into the network medium. It is influenced by the packet's size and the speed of the network link.
- Processing Delay : The time it takes for network devices like routers and switches to process and forward data packets. This can be affected by the performance of these devices and their configurations.
- Queuing Delay : The time data packets spend in queues at various points in the network, waiting for their turn to be processed. High congestion or network traffic can increase queuing delays.
- Jitter : Jitter refers to variations in latency. Inconsistent latency can affect the predictability of network performance, which is particularly critical for real-time applications.
II. Defining Network Round-Trip Time (RTT)
As we've already discussed in this article, RTT is a specific metric used to measure the time it takes for a data packet to travel from its source to its destination and back to the source . It is a subset of latency that focuses on the round-trip journey of a packet. RTT is measured in milliseconds (ms) and is often used to evaluate network responsiveness.
The RTT calculation typically involves the following timestamps:
- The time the sender sends the packet.
- The time the sender receives an acknowledgment (ACK) from the receiver.
- The time the receiver receives the packet.
- The time the receiver sends the ACK back to the sender.
By subtracting the appropriate timestamps, you can calculate the RTT for a specific packet.
In summary, latency is a broader term that encompasses various types of delays in data transmission, including RTT. RTT specifically measures the round-trip time for a packet, which is crucial for understanding the responsiveness of a network, particularly in applications that require timely data exchange, such as video conferencing or online gaming.
We asked a supercomputer “What is latency”, its impact on network performance, and strategies for minimizing it and created this comprehensive guide.
The Quest for Lower Network Round-Trip Time: How to Reduce Network RTT
In the quest for network optimization and superior user experiences, one metric stands as a sentinel of responsiveness - Network Round-Trip Time (RTT). A lower RTT signifies not only the swift transmission of data but also the realization of network efficiency, seamless applications, and satisfied users.
Here, we will explore the art of reducing RTT through a variety of carefully crafted strategies. From optimizing network topology to the art of content caching and compression, from harnessing the power of load balancing to the efficiency of Content Delivery Networks (CDNs), we will venture into the multifaceted realm of RTT reduction.
I. Strategies for Reducing Network RTT
Reducing RTT is a fundamental objective in optimizing network performance . So, there are several strategies to help you achieve this:
- Optimizing Network Topology : A well-designed network topology that minimizes the number of network hops and ensures efficient routing can significantly reduce RTT. Strategies like hierarchical network design and route optimization contribute to lower latency.
- Quality of Service (QoS) Implementation : Prioritizing real-time traffic and critical applications through QoS policies can reduce contention for network resources and lower RTT for those essential services.
- Edge Computing : Deploying computing resources closer to end-users or IoT devices at the network edge can reduce RTT by decreasing the physical distance that data needs to travel.
- TCP/IP Optimization : Fine-tuning TCP/IP parameters and employing technologies like TCP window scaling and selective acknowledgments can improve data transfer efficiency and lower RTT.
II. Load Balancing and Redundancy for Reducing Network RTT
Load balancing and redundancy are vital components in RTT reduction:
- Load Balancing : Distributing network traffic across multiple servers or paths ensures that no single server or network link becomes overwhelmed. This strategy not only increases network capacity but also reduces the likelihood of network congestion and high RTT.
- Redundancy : Implementing redundancy through network failover mechanisms or backup links can mitigate the impact of network failures. Redundancy ensures that if one path experiences issues, traffic can be rerouted quickly, minimizing RTT.
III. Content Delivery Networks (CDNs) for Reducing Network RTT
CDNs are instrumental in RTT reduction, particularly for web content delivery:
- Caching : CDNs cache content on servers located in geographically distributed edge locations. This means users can access content from a nearby server, reducing the need to retrieve data from the origin server, and consequently lowering RTT.
- Content Prioritization : CDNs allow prioritizing and delivering the most critical content quickly, which is especially beneficial for reducing RTT for web pages, images, and videos.
IV. Caching and Compression for Reducing Network RTT
Caching and compression techniques are powerful tools for minimizing RTT:
- Data Caching : Caching frequently accessed data locally, either at the client side or at intermediate network nodes, allows for quicker retrieval of data, reducing RTT.
- Data Compression : Compressing data before transmission and decompressing it at the receiver's end decreases the amount of data to be transferred, ultimately lowering RTT.
By implementing these strategies and technologies, network administrators and IT professionals can actively work to reduce RTT, enhance network performance, and deliver a more responsive user experience. Each strategy offers a unique approach to address latency and can be adapted to the specific needs and goals of the network environment.
Tools and Technologies for Optimizing Network Round-Trip Time: Network RTT Optimization
In the realm of network performance, the pursuit of lower Network Round-Trip Time (RTT) is both an art and a science. It requires the judicious selection and deployment of tools and technologies that act as enablers, elevating networks to realms of enhanced responsiveness and efficiency.
Here, we uncover the spectrum of tools at your disposal, explore their capabilities, and provide insights into the selection process to ensure you choose the right tools that align with your unique business needs. Earlier in this article, we already talked about measuring RTT and identifying RTT issues with Network Performance Monitoring tools - which are also a key tool for optimizing round-trip time.
With the right tools in your arsenal, you can orchestrate a network that not only understands the melody of RTT but dances to its tune, delivering a harmonious and responsive user experience.
I. Network Monitoring and Analytics Solutions for Optimizing Network RTT
Monitoring and analytics tools are instrumental in the quest for RTT optimization:
- Network Performance Monitoring (NPM) : NPM solutions continuously monitor network performance, providing real-time visibility into RTT metrics. They enable network administrators to detect and diagnose issues promptly, making them a vital tool for maintaining low RTT.
- Packet Capture and Analysis Tools : Packet capture tools allow the in-depth analysis of network traffic. Administrators can use these tools to capture and examine packets, enabling them to identify bottlenecks and other issues contributing to RTT delays.
- Network Traffic Analysis : Advanced network traffic analysis solutions provide insights into application behaviour, network usage , and patterns. These tools help optimize network paths and configurations to lower RTT.
II. SD-WAN and Network Optimization Platforms for Optimizing Network RTT
SD-WAN (Software-Defined Wide Area Network) and network optimization platforms offer dynamic solutions for RTT optimization:
- SD-WAN : SD-WAN technology leverages multiple network connections and dynamically routes traffic over the most efficient path. It includes features such as traffic prioritization and application-aware routing, which are beneficial for optimizing RTT for critical applications. The same goes for Dual-WAN networks .
- WAN Optimization Controllers : These devices optimize data traffic between WAN endpoints by employing techniques like data deduplication, compression, and caching. WAN optimization reduces the amount of data transferred, reducing RTT.
- Content Delivery Platforms : Content delivery platforms, combined with CDNs, accelerate the delivery of web content by distributing it to edge servers. This minimizes the physical distance data needs to travel, resulting in reduced RTT for web-based services.
III. Choosing the Right Tools for Optimizing RTT in Your Business
Selecting the right tools for RTT optimization requires careful consideration:
- Assessing Business Needs : Start by identifying the specific requirements of your business. Consider factors like the nature of your applications, your network topology, and your performance goals. This assessment guides the choice of tools and technologies.
- Scalability : Ensure that the selected tools and technologies can scale with your business as it grows. Scalable solutions can adapt to increased network demands without compromising RTT.
- Compatibility : The tools and technologies you choose should seamlessly integrate with your existing network infrastructure. Compatibility ensures smooth implementation and operation.
- Budget Considerations : Evaluate the cost of implementation and ongoing maintenance. Balancing your budget with the need for high-performance tools is vital to achieving cost-effective RTT optimization.
- Monitoring and Maintenance : Plan for continuous monitoring and maintenance of the chosen tools and technologies. Regular updates and adjustments are necessary to adapt to evolving network conditions and maintain low RTT.
By exploring the array of tools and technologies available for RTT optimization and making informed choices that align with your specific network requirements, you can ensure that your network operates at its peak performance, delivering low RTT and a seamless user experience.

Harnessing the Power of Round-Trip Time (Network RTT) Optimization for Business Success
In the fast-paced digital landscape, where every millisecond counts, optimizing Network Round-Trip Time (RTT) should be a top priority for network admins. Achieving low and consistent RTT not only enhances the user experience but also impacts business operations in numerous ways.
For businesses, RTT optimization means improved productivity, reduced downtime, and the ability to leverage real-time applications to their full potential. In e-commerce, it can translate to higher sales, as low latency/ good latency ensures swift page loads and seamless transactions. For video conferencing and collaboration tools, it means clearer communication and increased efficiency. In the realm of online gaming, it can be the difference between a competitive edge and a frustrating experience for gamers.
By harnessing the power of RTT optimization, businesses ensure that their digital offerings meet the high expectations of today's users and remain competitive in an ever-evolving market.
Measuring and Optimizing Network RTT with Obkio’s NPM Tool
To start measuring and optimizing RTT, you need the right tools, and Obkio's Network Performance Monitoring (NPM) tool stands as a valuable ally.
With Obkio, you can measure, monitor, and optimize RTT with precision. Get real-time insights into network performance, offering visibility into RTT metrics at various network points. Obkio equips network admins and IT professionals with the means to detect and resolve RTT issues promptly, ensuring that network operations remain seamless and efficient. With Obkio, you can proactively manage RTT, detect anomalies, and maintain low-latency network performance.
As you harness the power of Obkio's NPM tool, you're well-equipped to elevate your network to new heights of efficiency, ultimately contributing to the success of your business in a digitally connected world!
- 14-day free trial of all premium features
- Deploy in just 10 minutes
- Monitor performance in all key network locations
- Measure real-time network metrics
- Identify and troubleshoot live network problems
You can rest assured that we're not like those pushy Sellsy people - there's no catch here. We firmly believe in the excellence of our product, but if it's not the right fit for you, we understand and want what's best for you.
These might interest you
19 network metrics: how to measure network performance, how to measure latency, say goodbye to network headaches..
Get a live demo of Obkio now!
Did you know?

- Skip to main content
- Skip to search
- Skip to select language
- Sign up for free
Round Trip Time (RTT)
Round Trip Time (RTT) is the length time it takes for a data packet to be sent to a destination plus the time it takes for an acknowledgment of that packet to be received back at the origin. The RTT between a network and server can be determined by using the ping command.
This will output something like:
In the above example, the average round trip time is shown on the final line as 26.8ms.
- Time to First Byte (TTFB)
September 1, 2020
What is Network Round-Trip Delay?

Network Round Trip Delay Impact Application Performance?
Round trip delay (RTD), a.k.a. Round trip time (RTT), or ping time, is the duration of time it takes for a signal to reach its destination across a network and then for an acknowledgment signal to return to the originator. This measurement includes all delays caused by routing, transmission medium, and network traffic. The return signal does not have to follow the same path that the initial signal took.
How do you measure Network Round-Trip Delay?
Using standard ping tools found on most computers, network round trip delay can be tested easily from the command line. The ping time or ping rate is typically measured in milliseconds (ms). The standard ping is measured for either Round Trip Time (RTT) or Time to First Byte (TTFB). RTT is the total time it takes for a data packet to go from the client and return from the server, and it is the standard reporting measurement. TTFB is the time it takes for the server to get the first byte of client data, and should be half the time as RTT on the same path.
Application Performance and Network Round Trip Delay
Impact of RTT on Application Performance
Round trip delay is closely related to network latency. RTD is the measure on which network latency and network jitter are calculated, and because of this, it shares the same impacts that latency and jitter have on quality of service (QoS). As RTD increases so does network latency, and as the variance between RTDs in a transmission increases so does the jitter.
What are the factors that impact Round-Trip Delay (RTD)?
- Transmission Medium—Network traffic speed is limited by the physical connections that it travels through. Because a signal can only travel as fast as the medium of transport allows, understanding the slowest and fastest mediums along a signals route becomes crucial in controlling RTD. For example, fiber optic cable is roughly 100x faster than coax cable, and over greater distances mostly fiber optic is used. However, leading into most homes, some variation of metal cable is used for the internet. This means, at these points of medium change, we can expect there to be transmission delays as signal slows down to when passing from fiber optic to travel across the copper medium. Further, inside the home or office, the signal may then be sent to computers via wifi, changing medium once again.
- Local Area Network Traffic—Local network traffic causes congestion which can bottleneck the network. This directly impacts both transmitting and receiving signals from connected devices. For example, the use of streaming services by multiple devices on the same network will cause congestion, but for other users trying to send and receive transmissions they may experience increases in RTD.
- Server Response Time—On the opposite side of a transmission from the requesting user is the server response. How quickly a server can respond to a request will impact the RTD. In fact, this is a classic attack by cybercriminals, known as a denial-of-service attack (DoS) when a server is flooded by requests in order to overload it and either stall access or deny it completely. Based on this example, the main principle for servers is the number of requests it must attend to, the greater the amount, the more likely it will impact RTD .
- Internet Routing And Congestion—Perhaps the aspect affecting round trip delay that is least controlled by IT departments is the routing of a signal across the internet. A signal travels from sender to receiver and back through a route that will pass through any number of nodes along the internet. Each node has its own network traffic that the signal must pass through, which factors into the RTD calculation. Generally the greater number of nodes that the signal travels through the more congestion it must contend with and ultimately the longer the signal will take.
- Physical Distance Of Transmission—Closely related to the transmission medium, the physical distance a signal must travel to reach its destination is limited by the laws of physics and the speed of light. In most long distance transmissions, fiber optics use light to send massive amounts of data efficiently, but even that is not instantaneous.
Related Terms
Network Latency
Network latency is the duration of time it takes a data packet to travel from its source to its destination across a network. In terms of user experience, network latency translates to how fast a user’s action produces a response from a network, say how quick a web page accesses and loads over the internet, or the responsiveness of an online game to the gamer’s commands.
Experience what better network management looks like.
Related Assets

How to Set Network Monitoring Alerts in LiveNX

Retooling NetOps for a Multi-Cloud Future Presented by EMA and LiveAction
Netskope debuts as a Leader in the 2024 Gartner® Magic Quadrant™️ for Single-Vendor Secure Access Service Edge Get the report
- Why Netskope
Changing the way networking and security work together.
Learn why Netskope debuted as a leader in the 2024 Gartner® Magic Quadrant™️ for Single-Vendor Secure Access Service Edge
Netskope serves more than 3,400 customers worldwide including more than 30 of the Fortune 100
Read how innovative customers are successfully navigating today’s changing networking & security landscape through the Netskope One platform.
We partner with security leaders to help you secure your journey to the cloud.
Netskope One is a converged security and network as a service platform.
Plan your path toward a faster, more secure, and more resilient network designed for the applications and users that you support.
Netskope One powers greater business agility with lightning speed and dependable resilience.
Netskope One is a cloud-native platform that offers converged security and networking services to enable your SASE and zero trust transformation.
NewEdge is the world’s largest, highest-performing security private cloud.
Netskope NewEdge is the world’s largest, highest-performing security private cloud and provides customers with unparalleled service coverage, performance and resilience.
Netskope partners with the strongest companies in enterprise technology.
The Netskope Cloud Exchange (CE) provides customers with powerful integration tools to leverage investments across their security posture.
Protect against advanced and cloud-enabled threats and safeguard data across all vectors.
Intelligent Security Service Edge (SSE), Cloud Access Security Broker (CASB), Cloud Firewall, Next Generation Secure Web Gateway (SWG), and Private Access for ZTNA built natively into a single solution to help every business on its journey to Secure Access Service Edge (SASE) architecture.
Confidently provide secure, high-performance access to every remote user, device, site, and cloud.
Netskope Next Gen SASE Branch converges Context-Aware SASE Fabric, Zero-Trust Hybrid Security, and SkopeAI-powered Cloud Orchestrator into a unified cloud offering, ushering in a fully modernized branch experience for the borderless enterprise.
Netskope One SASE provides a cloud-native, fully-converged and single-vendor SASE solution.
Get your complimentary copy of the only guide to SASE design you’ll ever need.
Achieve agility and efficiency through digital transformation.
Meet the security challenges of today and tomorrow.
Embrace the regulatory frameworks shaping cybersecurity.
Netskope helps the largest agencies and enterprises in the world secure their journey to the cloud.
Choose Netskope GovCloud to accelerate your agency’s transformation.
Learn more about how Netskope can help you secure your journey to the cloud.
Neurodivergence in Cyber Host Emily Wearmouth sits down for a conversation about neurodivergence in cyber with special guest Holly Foxcroft, a neurodiversity consultant and expert on neurodiversity research in the cybersecurity industry.
Learn how Netskope enables security and networking transformation through secure access service edge (SASE)
Read how Netskope can enable the Zero Trust and SASE journey through secure access service edge (SASE) capabilities.
Stay ahead of the latest security trends and connect with your peers.
Learn how to navigate the latest advancements in SASE and Zero Trust and explore how these frameworks are adapting to address cybersecurity and infrastructure challenges
Everything you need to know in our cybersecurity encyclopedia.
Learn about the future convergence of networking and security tools in today’s cloud dominant business model.
We help you stay ahead of cloud, data, and network security challenges.
Netskope is proud to participate in Vision 2045: an initiative aimed to raise awareness on private industry’s role in sustainability.
We are here for you and with you every step of the way, ensuring your success with Netskope.
Netskope training will help you become a cloud security expert.
- A Leader in Security Service Edge (SSE)
- A Leader in Secure Access Service Edge (SASE)
- A Forrester Wave™ SSE Solutions Leader
- Experience Netskope
- Our Customers
- Case Studies
- Technology Partners
- Solution Providers
- Service Delivery Specialization
- Service Providers
- System Integrators
- Partner Portal

- Netskope One Overview
- The Power of One
- AI-Powered Visibility & Protection
- A Phenomenal User Experience
- Netskope Zero Trust Engine
- NewEdge Network
- Netskope One Gateway
- Netskope One Client
- Deployment Options
- NewEdge Overview
- Productivity Calculator
- NewEdge Blog Posts
- Technology Partners & Integrations Overview
- Our Technology Partners
- Cloud Exchange

- Security Service Edge (SSE)
- Next Gen Secure Web Gateway (SWG)
- Cloud Access Security Broker (CASB)
- Public Cloud Security
- Advanced Analytics
- Cloud Firewall
- Data Loss Prevention (DLP)
- Proactive Digital Experience Management
- Device Intelligence
- Remote Browser Isolation
- SaaS Security Posture Management
- Borderless SD-WAN
- Next Gen SASE Branch
- Secure SD-WAN
- Endpoint SD-WAN
- Micro Branch
- Wireless WAN
- Multi-Cloud Networking
- IoT Intelligent Access
- Secure Access Service Edge (SASE)

- Hybrid Work
- Replace VPNs
- Simplify Operations
- Advanced Threat Protection
- Data Protection
- Insider Risk
- Maintain Cloud Compliance
- Safely Enable ChatGPT and Generative AI
- Secure Managed Cloud Applications
- Secure Unmanaged Cloud Services
- AWS, Azure & GCP
- Financial Services and Insurance
- Healthcare and Life Sciences
- High Technology
- Higher Education Institutions
- Manufacturing
- US Public Sector
- UK Public Sector
- Retail and Hospitality
- Service Companies

- Resource Library
- Analyst Reports
- Compliance Guides
- Data Sheets
- Demos & Videos
- Product Documentation
- Reports & Guides
- Solution Briefs
- White Papers
- Security Visionaries Podcast
- Threat Labs
- Netskope Blog
- Behind the Scenes
- News & Announcements
- Platform, Products, & Services
- Netskope SASE Summit
- The SASE Accreditation
- Unpacking Webinar Series
- Webinars On-Demand
- Security Defined overview
- What is SASE?
- What is Security Service Edge?
- What is a Cloud Access Security Broker (CASB)?
- What is Zero Trust Network Access (ZTNA)?
- What is a Next Generation Secure Web Gateway (SWG)?
- What is Data Loss Prevention (DLP)?
- What is SD-WAN?
- What is Generative AI?
- What is SSPM?
- What is FedRamp?

- Corporate Overview
- Leadership Team
- Corporate Social Responsibility
- Diversity, Equity, and Inclusion
- Executive Briefing Program
- Security, Compliance & Assurance
- Professional Services
- Customer Success
- Technical Support
- Service Delivery Partners
- Customer Community
- Support Portal
- Trust Portal
- Netskope Security Cloud Introductory Online Technical Training
- Netskope Security Cloud Operation and Administration (NSCO&A)
- Netskope Security Cloud Implementation and Integration (NSCI&I)
- Netskope Cloud Security Certification Program

- Uncategorized
How to Measure Network Latency: The 5 Best Tools
Why test internet latency? Application latency has a large impact on user experience for web sites and applications. Testing latency provides insight into its origin. With the right tools you can determine if latency is caused by the internet or your network, your device or browser or the server or site you are connecting to. This article explains how to check internet latency, how to test latency and improve the user experience of your employees and website visitors.
We will explain how five common network latency test tools work so you can choose the right one to test the latency of your internet connection and application. Online latency test sites are not usually precise enough to reveal the cause, so let’s take a look at how to test latency like a pro!
Top 5 Network Latency Test Tools
The most common internet latency test tools are:
Each has their strengths and weaknesses when testing latency. Some network latency tests work well for internet latency, others are best suited to testing local or private network latency.
Ping and Traceroute Latency Testing
Ping and traceroute are latency tests you can perform from your PC. They can be used to test online and internet latency as well as to check latency in your local network.
Measure network latency with PING
Ping is the simplest approach to test network latency from your computer.
How ping works
Ping is a standard latency test tool available on all operating systems. It measures the round trip time (RTT) between your PC and the target you specify (domain or IP address). RTT is the time it takes for the ping packet to reach the target plus the time it takes to return the result, so it measures the total latency to get a response from a server, PC, router or internet site.
To use ping open a console or terminal window and type ping domain . If you provide a domain name (like google.com) ping will first verify that it can resolve the domain and report back its corresponding IP address. You can alternatively provide the IP address of the server you want to test latency to.
The following example shows that the minimum, maximum and average round trip latency times are 20ms, 24ms and 21ms respectively.
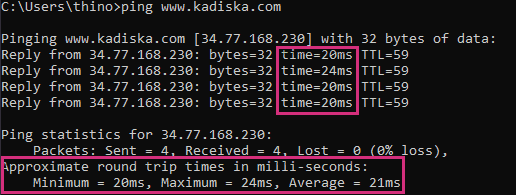
By default, a ping command tests latency by sending four ICMP Echo Request packets to the destination which responds back with ICMP Echo Reply packets which are then used to calculate latency.
The main advantage of this method is its simplicity. You do not need anything installed on your PC to test internet latency to any domain, or network latency to any IP address. It’s a good way to check if latency is a problem.
Limitations
Unfortunately, simplicity often comes with limitations.
First, for security reasons, ICMP packets may be blocked by an intermediate firewall. In this case, the target will never respond to your ICMP Echo Request and you will not be able to measure the network latency.
Second, the ICMP protocol may be handled with low priority by intermediate routers, distorting the accuracy of the latency measurements.
Finally, as ping measures the round trip delay you cannot differentiate the network latency in either direction (e.g. upload vs. download direction internet latency), so it is not possible to detect directional network latency problems. Directional latency problems regularly affect web conferencing applications like Zoom, Microsoft Teams and Google Meet.
Measure network performance with Traceroute
As an alternative to ping, you can check network latency with traceroute. This approach to testing latency is also available on all operating systems. From a terminal window, use these commands:
- tracert command on Windows machines
- traceroute command on Linux and Mac machines
How Traceroute works
Traceroute uses the TTL (Time To Live) field of IP packets to discover intermediate routers between a source and a destination. This technique tests latency to each hop along the network path and identifies them by IP address as it tests. This provides more insight into the origin of network latency problems.
The principle is simple. Each time a router forwards a packet its corresponding TTL field value is decremented by 1. When this value reaches 1, the router drops the packet and sends an ICMP Error message “TTL exceeded in transit” back to the source. This mechanism is used to prevent packets from looping indefinitely, which may cause the whole network to crash. In this case traceroute is taking advantage of this behaviour to check latency to intermediate locations.
Receiving ICMP packets back from intermediate routers allows the source to discover them as well as measure the network latency to reach them.
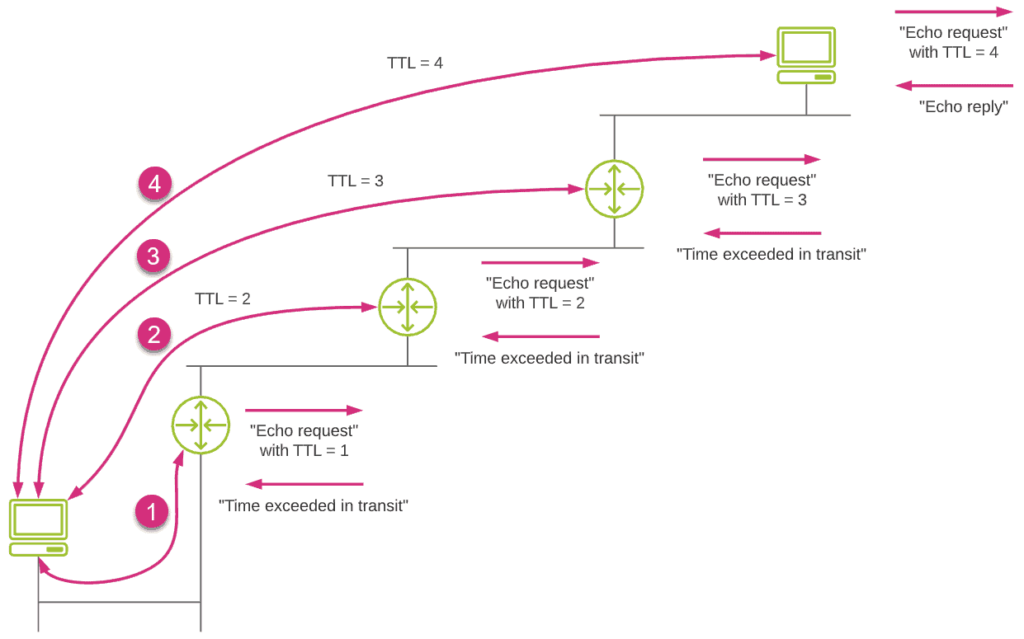
In its simplest form, traceroute uses ICMP protocol (Echo Request) for sending packets to test latency and discover the hops along the network path. Some routers may not respond to ICMP packets for security reasons. This means that latency testing will stop at this point, preventing you from checking latency end-to-end. You can see this in the image below.
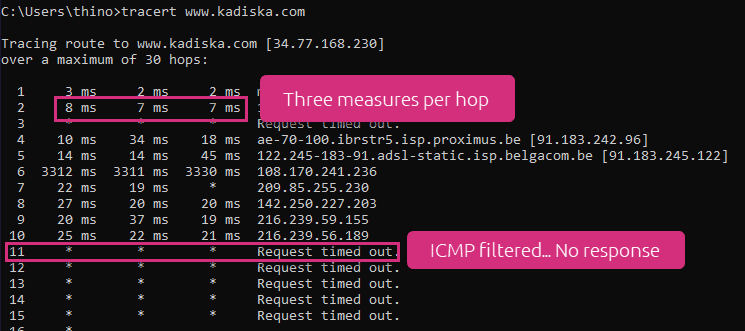
You can also see that traceroute sends four packets per hop by default on a Windows platform.
More advanced implementations also use UDP or TCP transport protocols, and offer more options (packet size, probe interval, number of probes per hop, …). This ensures that your latency tests are better aligned with real network traffic and the way that it’s routed. Nevertheless, all traceroute implementations still rely on the ICMP Echo Reply messages that are often processed with much lower priorities, impacting accuracy the same way ping latency tests are affected.
And just like ping, testing latency using traceroute returns the round trip delay. If your network connection is asymmetrical (like most broadband connections are), network latency measured by traceroute won’t allow you to check for directional network latency issues.
The main benefits of traceroute are:
- Easy to use and implement
- Gives a representation of the network path
Traceroute comes with some limitations:
- If traceroute uses ICMP, limitations affecting ping are also valid
- You can only check latency round trip
Advanced approaches to testing latency
More advanced synthetic latency testing techniques get around the problems introduced by testing latency with low priority ICMP packets, as well as the limitation of round trip latency measurements. Here are three of the most common.
OWAMP One Way Network Latency Testing
OWAMP stands for One-Way Active Measurement Protocol. It is standardized under RFC 4656 .
Compared to ping/traceroute, OWAMP tests network latency in one direction and does not rely on the ICMP protocol to calculate latency.
How OWAMP works
OWAMP provides more precise network latency measurements by using UDP packets to test latency in one direction. You can fine tune your latency tests to better align with your specific requirements and use case. For example, you can define the size of latency test packets, the interval between two consecutive packets in a test, as well as the number of packets per test.
And of course, it is easy to check if network latency is occurring in only one direction by performing an OWAMP latency test in each direction.
OWAMP latency test results are also more detailed than ping or traceroute. It provides the minimum, median, and maximum value of the network latency between your source and the targeted destination (as well as other useful data like one-way jitter and packet loss).
OWAMP latency testing also supports security authentication mechanisms.
So is OWAMP the ultimate way to test internet latency?
The answer is “Yes”, but only if you have OWAMP testing capabilities at both ends of the network connection. OWAMP requires the implementation of a client/server latency test architecture. A piece of software must be installed on both the source and the destination for the OWAMP latency test to work. Moreover, to get accurate one-way latency test results, both latency test points must have properly synchronized clocks. Some telecom-grade routers have native OWAMP support built in, but clock synchronization will still require a time server supporting a standard protocol like IEEE 1588v2 ( PTP ).
One more limitation: OWAMP does not properly support NAT (Network Address Translation) configurations, preventing you from checking latency across some internet / private network boundaries.
- One way network latency measurement
- High accuracy latency results
- Need OWAMP latency test capabilities at both ends
- Requires proper clock synchronization to measure one-way latency
- No NAT support
TWAMP for bidirectional latency testing
TWAMP, which stands for Two-Way Active Measurement Protocol, is a variation of OWAMP. It is standardized under RFC 5357 .
If you want to check latency in both directions at the same time, TWAMP is the answer.
How TWAMP works
TWAMP tests latency by first using TCP to establish a connection between the source and destination, then uses UDP packets to monitor the latency. It also uses a client/server architecture and requires that the endpoints support the TWAMP latency test protocol.
As a variation of OWAMP, TWAMP share the same latency test advantages and disadvantages:
- Need TWAMP latency test capabilities at both ends
Using iPerf to test network latency performance
iPerf , now in its thirdversion (iPerf3), is complementary to OWAMP and TWAMP. However, iPerf doesn’t test latency , as it is primarily designed to test throughput and packet transmission. iPerf is the technique frequently used for network speed testing by a variety of network test tools online.
How iPerf works
iPerf also uses a client/server model where data can be analyzed from both ends. iPerf measures throughput, jitter and packet loss.
- iPerf can use UDP as well as TCP to test network performance
- Configurable parameters mean tests can be aligned to a specific use case
- iPerf provides throughput information
- iPerf requires a client / server implementation (i.e. on both ends)
- iPerf doesn’t test network latency
Testing Latency – Summary of testing approaches
These five methods to test network latency and internet latency each offer advantages and disadvantages. This table summarizes these common techniques so you can pick the right test approach for private network latency testing vs. checking online or internet latency, for local networks or WANs.
In short, there is no best way to test latency. The test tool you pick should reflect your needs, as well as your ability to instrument both ends of the connection.
How to Test Latency – Conclusions
Being able to correctly test network latency is a key aspect to monitoring, troubleshooting and optimizing the performance and user experience of applications.
You can do simple latency tests with ping or traceroute commands from any PC, but bear in mind that these techniques suffer from some significant latency test limitations:
- Poor latency measurement precision due to the nature of ICMP test packet handling by routers and hosts.
- Only reports RTT latency, preventing ability to check latency in a specific traffic direction
On the other hand, if you manage both ends of the test a better option would be to use OWAMP or TWAMP to test latency. The measurements will be more precise, and you will be able to detect latency problems in each direction independently. It’s not easy to implement and orchestrate these latency tests in a distributed, complex production environment, so it’s typically used only by telecom service providers where network latency is critical to performance of their production networks.
At Netskope we find network latency, internet latency, application and cloud security latency a fascinating topic! Our Proactive Digital Experience Management (P-DEM) solution uniquely measures per-hop latency and its impact on real user experience by combining multiple vantage points for exceptional accuracy:
- a SMART combination of synthetic monitoring augmenting real traffic analysis
- device health metrics including CPU, memory, disk and network performance and utilization
- deep insight from our security proxies hosted in the NewEdge private cloud
This approach provides more than latency measurements from device to app, it can also pinpoint the source of latency at any point in between, such as PC, browser, WiFi, ISP, SD-WAN , Netskope SASE , cloud networks, or application hosting performance.
Learn more about digital experience and latency monitoring with these resources:
- P-DEM Visibility Overview and Demo Video
- P-DEM Product Page
- P-DEM Checklist
- P-DEM Data Sheet

Related Articles
Netskope Threat Labs Stats for November 2023
How to Troubleshoot Poor SaaS Performance?
Using Traceroute to Measure Network Latency and Packet Loss
Stay informed!
Subscribe for the latest from the Netskope Blog
Stack Exchange Network
Stack Exchange network consists of 183 Q&A communities including Stack Overflow , the largest, most trusted online community for developers to learn, share their knowledge, and build their careers.
Q&A for work
Connect and share knowledge within a single location that is structured and easy to search.
Data obtained from ping: is it round trip or one way?
I have 2 servers, each in two separate locations. I need to host an application on one, and the database server on the other.
From the app server, if I ping the database server, on average I get about 30ms.
My question is:
Is it going to take 30 ms + database_server_query_run_time
Is it going to take 30 ms + database_server_query_run_time + 30ms
I would like to understand this please.
3 Answers 3
It will usually take more then those two options.
Ping measures just the time from client, to server, and back again (rtt - round trip time)
Usually databases use TCP, so you first need to send a SYN packet to start the TCP handshake (to simplify let's say 15ms* + cpu time, then you recieve and SYN/ACK (15ms+cpu time), send back an ACK and a request (atleast 15ms + cpu time), then the time for the DB to process the query, and then the time (15ms + cpu) to get the data back, and a bit more to ack, and close the connection.
This is ofcourse not counting the authentication (username/password) to the database, and no encryption (ssl handshakes/DH or whatever is needed).
*half of a round trip time, assuming the route there and back is symmetrical (half the time to get there, and half to get back... cpu processing time for ping reply is very short)
- The problem of three-way-handshake could be encountered with persistent TCP sessions. – Michuelnik Commented Oct 15, 2012 at 12:57
- @Michuelnik, could you please elaborate? I would really like to understand this whole thing and find the best way to minimize the latency for querying the DB. – Phil Commented Oct 15, 2012 at 12:58
- 2 Sadly, most software (atleast web apps) dont's support this :/ But the idea is, to establish the connection (once) to the DB, and keep the connection running (open), and just keep sending queries/getting replys over one, constantly open connection. This eliminates the need for tcp handshakes, authentication, etc. each time. – mulaz Commented Oct 15, 2012 at 13:01
- mulaz, thank you for explaining. I'll be working with Python so we shall see how it goes. ;-) – Phil Commented Oct 15, 2012 at 13:42
- Don't forget the size of the request and the reply. For example, over a 1MB/sec link, a 100KB payload would take an extra 100ms to transport. – Dustin Boswell Commented Jun 26, 2014 at 3:01
The ping time is round trip. If you think about it -- how could it measure the one way time? So it will take 30ms plus the query time.
- 1 I'll just add that is probably going to take a bit longer than just the 30 secs +query time. since Ping is ICMP and your DB connection is TCP, you will also have setup/handshake, and DB Connection initiation etc in there as well – Doon Commented Oct 15, 2012 at 12:51
- @Doon: Which could be "avoided" with persistent TCP/database connections – Michuelnik Commented Oct 15, 2012 at 12:57
- @Michuelnik, do you think that persistent DB connection is the way to go here? Will it cause some other issues? – Phil Commented Oct 15, 2012 at 12:59
- @michuelnik , of course. Was just pointing out it isn't as simple as RTT + Query. There are also Limits to Max Speed, per session due to latency, etc..) – Doon Commented Oct 15, 2012 at 12:59
- @phil In most cases it Persistent DB connections are beneficial, if you are going to do be doing multiple queries. If queries are spread out /sporadic you are tying up resources unnecessarily, but if queries are coming all the time, etc. you will save a non trivial amount of overhead by reusing the existing connection as opposed to opening a new one on each request. – Doon Commented Oct 15, 2012 at 13:01
The ping time would represent all three together, so it would include the time from app to database server, the time the database query took to complete ( as it creates the timestamp for the response after the query is completed ), and the time it took in transit back to the app server round-trip.
So in short ping is the all-inclusive round trip time it took from a packet being sent to it's response arriving back round-trip.
The "ping" of a service is usually measured in the average of multiple pings, so a ping could mean one single packet sent or it could be referring to the average value of all of the round trip times. And so if you took the ping's round trip time value from the last 100 packets and all together they average 30ms, then you would say "it has a 30ms ping".
You must log in to answer this question.
Not the answer you're looking for browse other questions tagged networking ping latency ..
- The Overflow Blog
- Mobile Observability: monitoring performance through cracked screens, old...
- Featured on Meta
- Announcing a change to the data-dump process
- Bringing clarity to status tag usage on meta sites
Hot Network Questions
- How can one be honest with oneself if one IS oneself?
- Cannot see my own router IP in VM machine in Kali Linux
- Strange error during the use of `\newtheorem`
- Is there a way to isolate 2 operating systems on 2 different hard drives?
- Is 3 ohm resistance value of a PCB fuse reasonable?
- 2 in 1: Twin Puzzle
- Is there a nonlinear resistor with a zero or infinite differential resistance?
- If Starliner returns safely on autopilot, can this still prove that it's safe? Could it be launched back up to the ISS again to complete its mission?
- Where to donate foreign-language academic books?
- Can I endow the following 3-manifold with a hyperbolic metric?
- Maximizing the common value of both sides of an equation
- How can judicial independence be jeopardised by politicians' criticism?
- What is opinion?
- Seinfeldisms in O.R
- Reconstruction of Riemann surface from a germ of holomorphic function
- Journal keeps messing with my proof
- Should you refactor when there are no tests?
- Overstayed Schengen but can I switch to US passport?
- What does "CD military" mean on this sign at this crossing point between East Berlin and West Berlin? (June/July 1989)
- Why is GParted distributed as an ISO image? Is it to accommodate Linux needs as well as Windows needs?
- Can IRS make the taxpayer pay the costs of litigation if the latter loses the case?
- What counts as the Earth's mass? At which point would it increase or decrease?
- How did Oswald Mosley escape treason charges?
- How much easier/harder would it be to colonize space if humans found a method of giving ourselves bodies that could survive in almost anything?

Latency vs Round Trip Time: Understanding the Differences

As someone who works in the technology industry, I often come across the terms “latency” and “round trip time” (RTT). While both terms are related to network performance, they are not interchangeable.
Understanding latency and RTT is crucial for troubleshooting network issues and improving network performance. In this article, I will explain latency and RTT and how they differ.
Table of Contents
What is Latency?
Latency refers to the time it takes for a packet of data to travel from its source to its destination . It’s the measure of how long it takes for a packet to travel from one point to another. Latency is often measured in milliseconds (ms), and the lower the latency, the better the network performance.
Many factors can affect latency, including the distance between the source and destination, the number of hops the packet must take, and the network’s speed. For example, if you’re sending a packet from New York to Los Angeles, it will take longer for the packet to travel that distance than if you’re sending it from New York to Boston.
Similarly, if the packet must pass through multiple routers or switches, it will take longer to reach its destination than if it only had to pass through one.
What is Round Trip Time?
Round trip time, or RTT, measures the time it takes for a packet to travel from its source to its destination and then back again . It’s time it takes for a packet to make a round trip. RTT is also measured in milliseconds (ms), and like latency, the lower the RTT, the better the network performance.
RTT is affected by the same factors that affect latency, including distance, number of hops, and network speed. However, RTT also considers the time it takes for the destination to process the packet and send a response.
For example, if you’re sending a packet to a server that’s busy processing other requests, it will take longer for the server to respond, and thus, the RTT will be higher.
Differences between Latency and RTT
The main difference between latency and RTT is that latency only measures the time it takes for a packet to travel from its source to its destination, while RTT measures the time it takes for a packet to make a round trip.
Latency measures the time it takes for a packet to travel from one point to another. It’s the measure of one-way delay. RTT measures the time it takes for a packet to travel from its source to its destination and back again. It’s the measure of two-way delay.
Another important difference is that while latency only measures the time it takes for a packet to travel from one point to another, RTT considers the time it takes for the destination to process the packet and send a response.
For example, if you’re trying to access a website, the latency will measure the time it takes for the packet to travel from your computer to the server hosting it. The RTT will measure the time it takes for the packet to travel from your computer to the server hosting the website and back to the webpage.
Latency and RTT are network performance measures, but they measure differently. Latency measures the time it takes for a packet to travel from one point to another, while RTT measures the time it takes for a packet to make a round trip.
Understanding the difference between these two terms is crucial for troubleshooting network issues and improving network performance.
How to Measure Latency and RTT?
Several tools and methods can be used to measure latency and RTT. One of the most common tools is the ping command. The ping command sends a packet to a specified destination and measures the time it takes for the packet to return. The ping command can be used to measure both latency and RTT.
Another tool that can be used to measure latency and RTT is traceroute. Traceroute works by sending packets to a specified destination and measuring the time it takes for each packet to reach each hop along the way.
It also provides information about each hop, such as IP address and hostname. This tool is useful for identifying the source of network issues, as it can show where packets are getting delayed.
There are also specialized tools and services, such as Speedtest and Cloudping, that can be used to measure network performance. These tools typically provide more detailed information about network performance, such as upload and download speeds, and can be used to compare network performance between different locations and providers.
What are Some Ways to Improve Latency and RTT?
There are several ways to improve latency and RTT, but it’s important to understand that not all solutions will work in all situations. The most effective solutions will depend on the specific network and the root cause of the latency or RTT issues.
One common solution is to upgrade network hardware, such as routers and switches . This can improve network speed and reduce the number of hops packets must take, thereby reducing latency and RTT.
Another solution is to optimize network configurations. This can include optimizing routing protocols and adjusting packet size. This can help to improve network efficiency and reduce the number of hops packets must take, thereby reducing latency and RTT.
Optimizing network software and applications can also help to improve network performance. This can include optimizing web servers, databases, and other applications to reduce the time it takes for the destination to process packets and send a response.
Finally, it’s also essential to consider the physical location of network devices. For example, if devices are located in a poorly ventilated area, they may overheat and become less efficient, resulting in increased latency and RTT.
By moving the devices to a cooler location or adding additional cooling, the devices will be able to run more efficiently, which can help to improve network performance.
Latency and RTT are both important network performance measures, but they measure different things. Latency measures the time it takes for a packet to travel from one point to another, while RTT measures the time it takes for a packet to make a round trip.
Understanding these two terms’ differences is crucial for troubleshooting network issues and improving network performance. Several tools and methods can be used to measure latency and RTT.
There are several ways to improve network performance, such as upgrading network hardware, optimizing network configurations, optimizing network software and applications, and considering the physical location of network devices.
Frequently Asked Questions
Why is it important to understand the difference between latency and rtt.
Understanding latency and RTT is crucial for troubleshooting network issues and improving network performance. Latency and RTT are network performance measures, but they measure differently.
By understanding the difference between these two terms, you can better understand where network issues are occurring and implement solutions to improve performance.
Can latency and RTT be reduced to zero?
It’s impossible to reduce latency and RTT to zero, as there will always be some delay due to the physical distance between the source and destination.
However, latency and RTT can be minimized through various methods such as upgrading network hardware, optimizing network configurations, and reducing the number of hops packets must take.
Can you give an example of a situation where latency is more important than RTT?
One example of a situation where latency is more critical than RTT is in online gaming . When playing a game online, players expect a low latency to ensure that their actions are responsive and they have the best gaming experience.
In this case, it’s more important to minimize the time it takes for a packet to travel from the player’s computer to the game server than to measure the time it takes for a packet to make a round trip.
Related Posts

[Solved] File is Too Large for Destination File System

MSI vs Dell: Battle of the Best Gaming Laptops

Spectrum Modem Blinking Blue And White: How to Fix
Gpu artifacts: causes, solutions, and prevention.

How Is A Microprocessor Different From An Integrated Circuit

MSI vs Lenovo: A Comprehensive Comparison for Tech Enthusiasts

Tim has always been obsessed with computers his whole life. After working for 25 years in the computer and electronics field, he now enjoys writing about computers to help others. Most of his time is spent in front of his computer or other technology to continue to learn more. He likes to try new things and keep up with the latest industry trends so he can share them with others.
Leave a Comment Cancel reply
Save my name, email, and website in this browser for the next time I comment.
PingPlotter Professional
Troubleshoot unlimited connections from your computer.
Compare Products

PingPlotter Cloud
Monitor and troubleshoot remote connections anywhere from a centralized online dashboard.
- Resources Support Center Articles and News Fix Your Network Interpreting PingPlotter
- Solutions Contact Centers Legal IT VoIP
Desktop Licenses
Get a free 7 day trial of PingPlotter Cloud
Interpreting Data
- What Are Good Latency & Ping Speeds?

Latency? Packet loss? You might know the numbers, but what are they showing you? Here's how to tell if your internet connection's ok.
“It's either good, or it isn't.”
It would be nice if network connections were so simple. While you may feel like things aren't quite right, feelings aren't a great way to measure network quality. To find a problem or get someone else to take action (like an ISP), you need hard data.
The best network tools test a number of metrics you can use to evaluate the quality of a connection. Each tells a slightly different story about what problems might exist and how they contribute to the lackluster experience you're having. Understanding each metric, how it impacts your network, and what you should expect to see can make finding the root cause of any problem a ton easier.
Here are the stats we often look for when evaluating a connection. These values are based on our own tests, IT industry quality standards, and a little bit of old-fashioned science and math. A passable network should have:
- Latency of 200ms or below, depending on the connection type and travel distance
- Packet loss below 5% within a 10-minute timeframe
- Jitter percentage below 15%
- Mean Opinion Score of 2.5 or higher
- A bandwidth speed of...let's talk about that one.
But that's just a C- network. If you're looking to go from so-so to stellar, you may need to dig a little deeper.
As much as we wish it was, data transmission isn't instant. It takes time to get data to and from locations, especially when they're separated by hundreds or thousands of miles. This travel time is called latency.
To be specific, latency (or ping ) is the measure of how long it takes (in milliseconds) for one data packet to travel from your device to a destination and back.

Latency is one of the primary indicators of network performance quality. Most people desire a faster, more responsive experience, and latency is a major contributor. High latency can often result in laggy gameplay in online games (where what you're seeing onscreen doesn't seem to line up with what's happening in-game), constant stream buffering, and long page load times.
Knowing what makes a “good” latency is a bit more involved than just looking at a number. Latency is generally dictated by your physical distance and connection type. While we have a longer discussion on the topic , the short answer is you should expect to see 1ms of latency for every 60 miles between you and your endpoint, plus a base latency added by the type of connection you have:
- 0-10ms for T1
- 5-40ms for cable internet
- 10-70ms for DSL
- 100-220ms for dial-up
For example, on the average DSL connection, we would expect the round-trip time from New York to L.A. to be roughly 110ms (2,451 miles/60 miles per ms + 70ms for DSL). In general, we've found consistent latency above 200ms produces the laggy experience you're hoping to avoid.
Packet Loss
Files aren't transferred across your network fully formed. Instead, they are broken into easy-to-send chunks called packets. If too many of these packets fail to reach their destination, you're going to notice a problem.
The percentage of packet loss you experience over a given timeframe is another primary indicator of your network performance.

If a connection is suffering high packet loss, you're likely to experience unresponsive services, frequent disconnects, and recurring errors. On average, we consider a packet loss percentage of 2% or lower over a 10-minute timeframe to be an acceptable level. However, a good connection shouldn't see packet loss at all . If you're consistently experiencing packet loss of 5% or higher within a 10-minute timeframe , there is likely a problem.
When evaluating packet loss, it's important to remember some routers and firewalls are calibrated to ignore the type of packet used in many network tests. While one hop may experience 100% packet loss, it's not always indicative of your overall connection quality. Check out this knowledge base entry about packet loss to learn more.
While consistently-high latency is a clear indicator of a problem, a wildly-fluctuating latency can also result in network quality issues.

The variance of latencies experienced over a given period of time is known as packet delay variation or jitter . The idea is fairly straightforward: When packets arrive at rapidly alternating speeds (fast, slow, fast, slow), the gaps between them create an inconsistent flow that negatively impacts real-time services, such as voice or video calls.
Jitter, which is measured in milliseconds, is calculated a few different ways. One method averages the deviation of latency samples and compares them to the average latency value across all samples to evaluate its impact.
So, let's say you pinged a server five times and got these results (in this order — that matters): 136ms, 184ms, 115ms, 148ms, 125ms. To calculate the jitter, you'd start by finding the difference between the samples, so:
- 136 to 184, diff = 48
- 184 to 115, diff = 69
- 115 to 148, diff = 33
- 148 to 125, diff = 23
Next, you'd take the average of these differences, which is 43.25. The jitter on our server is currently 43.25 ms.
So...is that good? To find out, we divide our jitter value by the average of our latency samples:
- 43.25 / 141.6 (the average of our five samples) = 30.54%
A “stable” network typically experiences a jitter percentage of 15% or below (based on our observations). In the example above, the jitter is nearly double that, which means jitter may be the cause of any issues we're experiencing.
Mean Opinion Score
Given everything we just described, you may be asking, is there a number that just says whether my connection is good or not? Conveniently, there is! The Mean Opinion Score (or MOS ) of a network is a straightforward one-to-five ranking of its overall quality.
Traditionally, MOS is calculated by polling individuals on how they would personally rate their experience using a specific connection ( this surprisingly fascinating history of MOS can help explain the details). In the case of network testing tools like PingPlotter, MOS is approximated based on the latency, packet loss, and jitter of your current connection using a dedicated formula.
For most people, MOS ratings of 4 or higher are considered “good,” while anything below 2.5 is considered unacceptable.
What about bandwidth?
The “speed” of a connection is probably the biggest thing people care about when it comes to their network (other than it just working as it should). Everyone wants faster downloads, better-quality streams, and instantly-accessible webpages, which is often tied to network bandwidth. Bandwidth is the rate at which a volume of data transfers over time, usually measured in bits-per-second.
Why the scare quotes? Most people, including ISPs and other providers, love to talk about bandwidth and speed in the same sentence. However, bandwidth isn't actually about the speed of data's traversal — it's about the quantity of data transferred over a given time period, and understanding the difference between the two will save you a ton of headache when diagnosing a problem.
If your network connection was a highway, latency would be how long it takes one car to get from point A to point B under current road conditions, while bandwidth would be how many cars arrive at point B every second regardless of how fast they're going. If you're worried about things like in-game lag, it's less about how many cars you can push through and more about making sure your cars are the fastest.
Once again: Latency is speed , bandwidth is flow .
When solving a network problem, your bandwidth may be a symptom, but it's not a great metric for finding the source of your issue. This is because bandwidth is really only measurable at the endpoints of a connection, which limits its efficacy.
Let's go back to our data-highway. If there were a bunch of lane closures somewhere between A and B, we might notice fewer cars arriving at point B, but we wouldn't know much more than that. Is there a problem on the highway? Yep! Can you tell what it is? Nope! By using the metrics we mentioned above in combination with the right tool, however, we can dig into what the problem actually is.
Bandwidth matters for a lot of things, but it's not the best way to test your connection.
Light is green, connection's clean
So, is your connection in rock-solid shape? If not, it's time to do something about it. Grab a trusty network test tool and get pinging!
Once you're ready, we have step-by-step guides on troubleshooting your connection , identifying common problems , and more.
Do you support remote workers?
When remote workforces have connection trouble PingPlotter Cloud helps you find the problem and get everyone back online fast.
- Running A Bandwidth Saturation Test
- Is PingPlotter Safe
- The Difference Between Latency & Packet Loss
- A Small Business Guide to Incorporating a VoIP System
- Learn How to Use Pingplotter for Games
- How to solve common Voip issues
- Why One Ping Only Tells Part of the Story
- What to Do Router Isn't Working After Reset
- Find The Device Slowing Down Your Network
- How to Optimize Remote Work Team Communication With VoIP
- Maximize Profits by Optimizing Your Service Team
- Reheating a Router: Is the Microwave Cooking Your WiFi?
- Differences Between TCP, UDP, and ICMP
- For Solving Wireless Network Problems, Knowledge is Power
- VoIP Troubleshooting Guide
- A Broadcast Storm Defined & How to Fix It
- How to troubleshoot Microsoft Teams
- How to troubleshoot Slack
- How to troubleshoot Zoom
- And the Best Ping Tool is...
- New to remote management? Here's how to keep everyone online
- Proving Your Internet Was Down
- Troubleshooting in the Time of COVID-19
- Why Perspective Matters for Network Testing
- When supporting remote teams, are RMMs really the best fit?
- PingPlotter Helps Ruby Answer the Call of Remote Work
- What IT Can Learn From the Cloud-Connected Firm
- Rethinking Internet Health Beyond Speed Tests
- About PingPlotter Sharing
- The Reviews are In: Mean Opinion Score is More Than a Rating
- How to Find Devices on Your Network with Network Discovery
- Find the IP Address of any IoT Device
- Troubleshoot Your Way with Flex Storage and Final Hop Only
- Getting Help with PingPlotter Share Pages
- Helping with PingPlotter Share Pages
- How to Deploy PingPlotter Wherever You Need
- For Service Providers, it Pays to be Proactive
- Mobile & Desktop Collaboration Tips
- Make Troubleshooting a Picnic with NIC Selection
- PingPlotter's Web Interface Takes Your Network to the Net
- Network Route Changes Can Lead to Payday — or Peril
- Stay on Top of Trouble with PingPlotter Alerts
- Founder's Perspective on PingPlotter 5
- Cut Through Confusion With PingPlotter Reports
- Be the hero with PingPlotter Sidekick
- Team up with PingPlotter's All-Hands update
- Plot a course with Quick Links
- Introducing PingPlotter Cloud
- Up your accuracy with the latest PingPlotter update
- Leave the app behind with PingPlotter's web UI
- How PingPlotter Helped a Law Firm Support Remote Workers
- An important PingPlotter update
- Get a head start with PingPlotter Cloud’s Agent presets
- What Legal IT Can Learn From the Cloud-Connected Firm
- Assisted Network Troubleshooting with PingPlotter Insights
- End-User Takes Center Stage in New PingPlotter Release
- PingPlotter Cloud’s New Dashboard — Widgets that Work
- Remote Agent Internet Impacts your Contact Center's CX and Profitability
- How to Pre-Qualify Remote New-Hire Networks
- Enhancing Operational Efficiency with PingPlotter Cloud's Updated Alerts
- PingPlotter’s Quick Guide to Customer Contact Week
- Navigating the Intersection of AI, Connectivity, and Hiring Reliability
- A Beginner's Guide To Anomaly Detection and its Role in the Network
- Bandwidth vs Latency — 4 Vital Differences
- How to See All of your Internet Connections in One Place
- How Many Traces Do I Actually Need?
- Instant Feedback Empowers You to React Within Seconds
- How to Use Distributed Network Monitoring
- How to Keep a Record of Network Performance Over Time
- How to Manage a Contact Center Team Using PingPlotter
Test end-user internet
PingPlotter Cloud helps solve network problems for other people.
Test your own internet
PingPlotter Standard & Professional help solve problems on your own network.
- Engineering Mathematics
- Discrete Mathematics
- Operating System
- Computer Networks
- Digital Logic and Design
- C Programming
- Data Structures
- Theory of Computation
- Compiler Design
- Computer Org and Architecture
What is RTT(Round Trip Time)?
RTT (Round Trip Time) also called round-trip delay is a crucial tool in determining the health of a network. It is the time between a request for data and the display of that data. It is the duration measured in milliseconds.
RTT can be analyzed and determined by pinging a certain address. It refers to the time taken by a network request to reach a destination and to revert back to the original source. In this scenario, the source is the computer and the destination is a system that captures the arriving signal and reverts it back.

RTT(Round Trip Time) Measurement
What Are Common Factors that Affect RTT?
There are certain factors that can bring huge changes in the value of RTT. These are enlisted below:
- Distance: It is the length in which a signal travels for a request to reach the server and for a response to reach the browser,
- Transmission medium: The medium which is used to route a signal, which helps in faster transfer of request is transmitted.
- Network hops: It is the time that servers take to process a signal, on increasing the number of hops, RTT will also increase.
- Traffic levels: Round Trip Time generally increases when a network is having huge traffic which results in that, for low traffic RTT will also be less.
- Server response time: It is the time taken by a server to respond to a request which basically depends on the capacity of handling requests and also sometimes on the nature of the request.
Applications of RTT
Round Trip Time refers to a wide variety of transmissions such as wireless Internet transmissions and satellite transmissions. In Internet transmissions, RTT may be identified by using the ping command. In satellite transmissions, RTT can be calculated by making use of the Jacobson/Karels algorithm.
Advantages of RTT
Calculation of RTT is advantageous because:
- It allows users and operators to identify how long a signal will take to complete the transmission.
- It also determines how fast a network can work and the reliability of the network.
Example: Let us assume there are two users, one of which wants to contact the other one. One of them is located in California while the other one is situated in Germany. When the one in California makes the request, the network traffic is transferred across many routers before reaching the server located in Germany. Once the request reverts back to California, a rough estimation of the time taken for this transmission could be made. This time taken by the transmitted request is referred to as RTT. The Round Trip Time is a mere estimate. The path between the two locations can change as the passage and network congestion can come into play, affecting the total period of transmission.
How Does Round-Trip Time Work?
Consider a topology where an appliance named “Exinda” is located between the client and the server. The diagram shown below depicts how the concept of RTT works:

RTT Calculation
For the calculation of Average RTT, RTTS for server and client needs to be calculated separately. The performed calculations are shown below:
Server RTT: RTT1 = T2 – T1 RTT2 = T5 – T4
Client RTT: RTT3 = T3 – T2 RTT4 = T7 – T6
Average RTT: Avg Server RTT = (RTTs1 + RTTs2) / 2 Avg Client RTT = (RTTc1 + RTTc2) / 2 Avg Total RTT = Avg Server RTT + Avg Client RTT
You can refer to the Program to calculate RTT for more details.
Measures To Reduce RTT
A significant reduction in RTT can be made using Content Delivery Network (CDN) . A CDN refers to a network of various servers, each acquiring a copy of the content on a particular website. It addresses the factors affecting RTT in the enlisted ways:
- Points of Presence (PoP)
- Web caching
- Load distribution
- Scalability
- Tier 1 access
CDN has been largely successful in reducing the value of RTT and due to this, a decrease in RTT by 50% is achievable.
Please Login to comment...
Similar reads.
- California Lawmakers Pass Bill to Limit AI Replicas
- Best 10 IPTV Service Providers in Germany
- Python 3.13 Releases | Enhanced REPL for Developers
- IPTV Anbieter in Deutschland - Top IPTV Anbieter Abonnements
- Content Improvement League 2024: From Good To A Great Article
Improve your Coding Skills with Practice
What kind of Experience do you want to share?
IMAGES
VIDEO
COMMENTS
Factors Influencing RTT. Actual round trip time can be influenced by: Distance - The length a signal has to travel correlates with the time taken for a request to reach a server and a response to reach a browser.; Transmission medium - The medium used to route a signal (e.g., copper wire, fiber optic cables) can impact how quickly a request is received by a server and routed back to a user.
Generally, it's a delay of some sort - application latency is the reaction time of an application (from input to output), network latency the delay for getting a packet from point A to B and so on. ... Round-trip time and ping time are often considered synonymous. While ping time may provide a good RTT estimate, it differs in that most ping ...
In telecommunications, round-trip delay (RTD) or round-trip time (RTT) is the amount of time it takes for a signal to be sent plus the amount of time it takes for acknowledgement of that signal having been received. This time delay includes propagation times for the paths between the two communication endpoints. [1] In the context of computer networks, the signal is typically a data packet.
Here's an example showing the ping command for google.com. You can use -c to limit the number of requests you want to send. Once the process is done, you'll get a summary of the RTT. ... RTT (Round Trip Time) is the two-way delay. It is the time taken by a network packet to travel from sender to receiver and then back to sender from the receiver.
The round-trip time (RTT) from the client's network to the AWS Region that the WorkSpaces are in should be less than 100ms. If the RTT is between 100ms and 200ms, the user can access the WorkSpace, but performance is affected. If the RTT is between 200ms and 375ms, the performance is degraded. If the RTT exceeds 375ms, the WorkSpaces client ...
What is round-trip time? Round-trip time (RTT) is the duration in milliseconds (ms) it takes for a network request to go from a starting point to a destination and back again to the starting point. RTT is an important metric in determining the health of a connection on a local network or the larger Internet, and is commonly utilized by network ...
Round-trip time (RTT) in networking is the time it takes to get a response after you initiate a network request. When you interact with an application, like when you click a button, the application sends a request to a remote data server. Then it receives a data response and displays the information to you. RTT is the total time it takes for ...
3. Round Trip Time. The RTT is the time between sending a message from a source to a destination (start) and receiving the acknowledgment from the destination at the source point (end). We can also see RTT referred to as Round Trip Delay (RTD). Sometimes, the acknowledgment is sent from the destination to the source almost immediately after the ...
Propagation delay is the network distance between the two endpoints. It is the route taken by the data across the various networks, through different network switches and routers to get from the sending endpoint to the receiving endpoint. ... resulting in a lower round-trip time. Clearing Up a Few Misconceptions. RTT and ping time are often ...
Round-Trip Time is a network performance metric representing the time it takes for a data packet to travel from the source to the destination and back to the source. It is often measured in milliseconds (ms) and is a crucial parameter for determining the quality and efficiency of network connections. To understand the concept of RTT, imagine ...
The Round Trip Time (RTT) mirrors the comprehensive duration a data segmentation spends journeying from its origin, reaching the receiver, and retracing its path. It offers an insight into network delay or latency. An escalated stretch covered by the segmentation amplifies the RTT, subsequently depreciating the network's efficiency.
December 8, 2022 5 min read. Round-trip time (RTT) is the time it takes for the server to receive a data packet, process it, and send the client an acknowledgement that the request has been received. It is measured from the time the signal is sent till the response is received. When a user clicks a button on a website, the request is sent to ...
First, let's make sure we're all on the same page. Network Round-Trip Time (RTT) in networking, also commonly referred to as Round-Trip Latency or simply Latency, is a crucial metric that measures the time it takes for a packet of data to travel from its source to its destination and back again to the source.RTT is typically expressed in milliseconds (ms) and is a fundamental aspect of ...
11. RTT is "round-trip time", it's the delay between sending the packet and getting the response; the * s mean that the timeout was reached before getting a response. Three numbers are provided from three different packets to give you a better sampling of the delay to that host. +1 yes, the results from three packets are provided so that you ...
Round Trip Time (RTT) is the length time it takes for a data packet to be sent to a destination plus the time it takes for an acknowledgment of that packet to be received back at the origin. The RTT between a network and server can be determined by using the ping command. This will output something like: In the above example, the average round ...
Round trip delay (RTD), a.k.a. Round trip time (RTT), or ping time, is the duration of time it takes for a signal to reach its destination across a network and then for an acknowledgment signal to return to the originator. This measurement includes all delays caused by routing, transmission medium, and network traffic.
Finally, as ping measures the round trip delay you cannot differentiate the network latency in either direction (e.g. upload vs. download direction internet latency), so it is not possible to detect directional network latency problems. Directional latency problems regularly affect web conferencing applications like Zoom, Microsoft Teams and ...
7. You shouldn't need to use traceroute for average RTT to a specific destination. You can just use ping for that. If that is what you are trying to do, then just average the 'time' field in the output from the ping command over several packets. If you are actually trying to get the average RTT to each hop along the path to a destination, then ...
While Philipp is mostly right, a ping may not be identical to the round-trip time. It differs in that most ping tests are executed within the transport protocol using ICMP packets. In contrast, RTT is measured at the application layer and includes the additional processing delay produced by higher level protocols and applications (e.g. HTTPS).
The "ping" of a service is usually measured in the average of multiple pings, so a ping could mean one single packet sent or it could be referring to the average value of all of the round trip times. And so if you took the ping's round trip time value from the last 100 packets and all together they average 30ms, then you would say "it has a ...
The main difference between latency and RTT is that latency only measures the time it takes for a packet to travel from its source to its destination, while RTT measures the time it takes for a packet to make a round trip. Latency measures the time it takes for a packet to travel from one point to another. It's the measure of one-way delay.
10-70ms for DSL. 100-220ms for dial-up. For example, on the average DSL connection, we would expect the round-trip time from New York to L.A. to be roughly 110ms (2,451 miles/60 miles per ms + 70ms for DSL). In general, we've found consistent latency above 200ms produces the laggy experience you're hoping to avoid.
Last Updated : 13 Apr, 2023. RTT (Round Trip Time) also called round-trip delay is a crucial tool in determining the health of a network. It is the time between a request for data and the display of that data. It is the duration measured in milliseconds. RTT can be analyzed and determined by pinging a certain address.
PING frames (Section 19.2 of [QUIC ... a sender can use the extension in this draft to request a receiver to send an acknowledgment at least once per round trip ... no acknowledgments will be received for at least a round trip when sending resumes. The max_ack_delay and Ack-Eliciting Threshold values used by the receiver can further delay ...